딥러닝 이야기 / Manifold Learning / 1. Autoencoder (오토인코더)

작성일: 2022.02.05
시작하기 앞서 틀린 부분이 있을 수 있으니, 틀린 부분이 있다면 지적해주시면 감사하겠습니다.
딥러닝 이야기의 첫 번째 주제는 manifold learning의 autoencoder (오토인코더) 입니다.
딥러닝은 아직 실생활에 완벽하게 적용하기에는 한계가 있는 점은 분명합니다.
하지만 최근 vision, NLP 등 여러 분야에서 사람들보다 뛰어난 성능을 가지는 알고리즘이 많이 등장하고 있으며, 가장 대표적인 예로는 유명한 알파고가 있겠지요.
그리고 기존에 사람이 하지 못했던, 혹은 하더라도 오래 걸리던 작업이 딥러닝을 이용하면 높은 정확도로 해결이 되는 경우도 많아지고 있습니다.
또한 빅데이터가 많아짐에 따라 분석이 필요한 데이터들이 생겨나고 혹은 분석을 하고 싶은 부분도 많아지는 것도 사실입니다.
따라서 최근에는 전산학과 전공이 아니더라도 비전공자분들도 딥러닝을 접해보신 분들도 많으며, 계속 꾸준히 사용하는 사람들도 많습니다.
따라서 저는 아주 간단한 linear layer (PyTorch: Linear, tensorflow: dense)를 쌓아서 과제를 수행하는 아주 간단한 이야기는 다루지 않으려고 합니다(물론 추후에 간단하게 설명을 해볼까 합니다).
물론 딥러닝의 가장 초기의 형태인 linear layer를 이용한 간단한 MLP (Multilayer Perceptron), XOR 문제의 해결 등도 딥러닝이 발전하는 데 있어 큰 기여를 했습니다.
다만 저는 딥러닝의 조금 더 학술적이고, 딥러닝 분야에서 특별한 의미를 가지는 알고리즘, 모델들을 설명하고 구현하는 데 초점을 맞추려 합니다.
따라서 딥러닝에 대해 조금 깊게 어렵지 않은 선에서 알고 싶은 분들이 쉽게 생각을 정리하고, 적용해보는 데 도움이 되는 글을 적고자 합니다.
바로 지금 소개할 모델이 바로 앞으로 분야를 막론하고 딥러닝을 접할 때 주야장천 듣게 될 feature 추출 (특징 추출)과 아주 깊은 연관이 있는 autoencoder (오토인코더)입니다.
오늘의 컨텐츠입니다.
- 잠재 변수 표현
- 매니폴드
- 오토인코더
- 오토인코더의 구조
- 매니폴드 학습을 위한 모델 & 오토인코더의 종류
- 오토인코더의 응용
오토인코더
Autoencoder
Latent Variable Representation ”
먼저 autoencoder (오토인코더)를 설명하기 앞서 잠재 변수(Latent Variable)을 짚고 넘어가려 합니다.
잠재 변수는 데이터에 직접적으로 보이지 않지만 어떠한 데이터 분포를 만드는데 큰 역할을 하는 변수라고 보시면 됩니다.
예를 들어 내가 가지고 있는 데이터가 사람 사진이라고 가정을 하면, 사람들은 이 사진이 여자인지, 남자인지 높은 확률로 구분할 수 있을 것입니다.
아래 사람 사진의 예시를 보면 우리는 왼쪽이 여자고 오른쪽이 남자라는 사실을 알 수 있을 겁니다. 하지만 컴퓨터는 이를 어떻게 분간할 수 있을까요?
만약 우리가 현재 여자와 남자를 구분하는 과제를 수행 중이라 가정한다면, 컴퓨터는 아래 사진들을 보고 사진 속의 사람이 수염 유무, 머리 길이, 화장, 장신구 등 사진에서 많은 특징들을 추출할 것입니다.
하지만 우리는 이 사진들을 보고 감각적으로 이 사람이 여자인지 남자인지 구분을 하지만, 컴퓨터는 그럴 수 없는 노릇이죠. 그럼 컴퓨터는 어떠한 방식으로 사진들의 특징을 추출할 수 있을까요?

사람 데이터 예시
아래 예시를 보겠습니다. 먼저 가로와 세로의 크기가 각각 28 픽셀인 흑백 이미지가 있다고 가정하겠습니다.
흑백 이미지이므로 채널의 수는 1로 가정하여(RGB 값이 없음) 그 크기가 1×28×28이지만, 1을 생락하여 28×28로 나타내었습니다.
각각의 이미지의 픽셀들은 0과 1사이의 gray-scale의 값을 가지고 있을 것이며, 이또한 28×28로 표현할 수 있습니다.
우리는 이 픽셀들을 모두 이어붙여서 28×28의 이미지 형태에서 1×784의 벡터 형태로 나타낼 수 있습니다.
이렇게 나란히 벡터로 표현한 이유는 우리가 잘 아는 linear 혹은 hidden layer를 거치기 위함입니다.
이렇게 이미지를 벡터화한 데이터에 non-linear (linear layer or hidden layer) 변환 혹은 linear 변환과 같은 모종의 변환 과정을 거쳐 4차원의 데이터로 만든다고 가정하면, 총 784개(28×28)의 픽셀 값을 가지던 이미지는 각각 4개의 값으로 표현할 수 있습니다. 그리고 이렇게 4개의 값으로 표현 된 것이 바로 잠재 변수입니다.
그리고 딥러닝 모델은 잠재 변수를 바탕으로 사용자가 원한는 task를 수행하며, 그 task의 loss function(손실 함수)에 맞춰 최적의 잠재 변수를 추출하려 노력할 것입니다.
모델이 학습이 됨에 따라 어느 하나의 데이터에서 추출되는 잠재 변수 값은 학습을 하는 도중에는 계속 바뀌게 됩니다(계속 학습을 하면서 최적의 잠재 변수를 찾기 때문).
그리고 최종적으로 모델 학습이 완료 되었다면 그 모델은 어느 하나의 데이터에 대해 같은 잠재 변수를 내어줄 것이며, 여러 데이터가 들어왔을 때 각 데이터들의 특징을 잘 잡을 수 있는 각각의 잠재 변수를 만들어서 task를 수행하게 될 것입니다.
즉 컴퓨터 혹은 딥러닝 모델은 이러한 방식으로 잠재 변수를 추출하며 이것이 컴퓨터가 사진, 즉 데이터의 특징을 추출하는 방법입니다.
이러한 잠재 변수의 형태와 잠재 변수가 존재하는 잠재 공간(latent space)은 데이터의 종류와 수행하는 과제에 따라 다 다를 것입니다.
컴퓨터는 이렇게 구한 잠재 변수를 이용하여 이진 분류(binary classification), 다중 분류(multi-label classification), 회귀(regression), 단어 임베딩(word embedding) 등 사용자가 지정한 과제를 수행하게 됩니다.
이런 과제 중, 현재 설명하려는 것이 바로 압축 (compression)이며, 더 자세하게는 이미지 압축을 예시로 들어 설명을 진행하고 있습니다.

잠재 변수 변환 과정
아래의 각 이미지에서 추출한 잠재 변수가 다음과 같이 의미를 가진다고 가정해보겠습니다.
첫 번째는 짧은 머리인지, 두 번째는 넥타이가 없는지, 세 번째는 화장을 했는지, 네 번째는 수염이 있는지 여부를 확률로 알려주는 값이라고 해보겠습니다.
그럼 여자 사진에서 여자는 머리가 길기 때문에 첫 번째 잠재 변수 값은 낮은 값이 나올 것이며, 여자는 넥타이가 없기 때문에 두 번째 값은 높게 나올 것입니다. 남자의 사진에서는 반대로 나올 것이고요.
그리고 마지막 값에서 여자와 남자 모두 수염이 없으니 0.5에 가까운 값이 나올 것입니다.
만약 사용자가 사진이 여자인지 남자인지 구분을 하고싶다고 하면 딥러닝 모델은 내부에서 데이터에서 의미있는 잠재 변수를 추출하려 노력할 것이고, 이렇게 추출한 잠재 변수를 바탕으로 최종적으로 사진이 여자인지 남자인지 구분할 것입니다.
따라서 잘 학습된 모델은 어떠한 사진이 들어와도 들어온 사진에 대해 의미있는 잠재 변수를 잘 추출할 것이고, 구분도 잘하게 될 것입니다.
각 이미지의 잠재 변수 표현
위에서는 예를 들기 위해 잠재 변수 4개의 값에 각각 의미를 부여했지만, 실제로는 사람이 각 잠재 변수가 어떤 것을 의미하는지 알 수 없습니다.
그리고 잠재 변수는 보통 4차원이 아닌 128차원, 256차원과 같이 몇 백차원을 넘나듭니다. 따라서 각 데이터의 잠재 변수가 어떤 것을 의미하는지 알기는 어렵습니다.
따라서 많은 사람들이 딥러닝 모델을 모델 안쪽을 알 수 없는 black-box model이라 부르는 것입니다.
번외로 이러한 해석 불가능 모델은 healthcare 분야에서 매우 민감하게 작용합니다. 왜냐하면 딥러닝 모델이 사람의 건강 혹은 목숨과 직결되는 과제를 수행할 수 있기 때문입니다.
이러한 모델의 설명 불가능성을 해결하기 위해서 attention mechanism이 등장하였고, 이 attention mechanism도 non-linearity를 가지고 있다 주장하여 linearity attention mechanism도 등장하였습니다.
따라서 현재 많은 사람들이 설명 가능(interpretability, explainability) 딥러닝을 연구하고 있으며 이를 XAI (eXplainable AI)라고 부릅니다.
Manifold ”
Autoencoder는 manifold learning (매니폴드 러닝)을 위한 모델 구조입니다.
그럼 manifold란 무엇일까요? Manifold는 바로 모든 데이터를 최대한 오차 없이 잘 아우를 수 있는 subspace (부분 공간)를 의미합니다.
예를 들어 위에서 예시로 보여준 사진은 한 사진당 모두 784개의 픽셀을 가지고 있으며, 이는 각 데이터가 784차원이라고 볼 수 있습니다.
즉 데이터 각각을 784차원의 공간에 점을 찍어 각 데이터가 찍힌 점들을 분석하여 각 데이터의 특징을 반영하여 모든 데이터들을 잘 아우를 수 있도록 하는 공간이 바로 manifold (매니폴드) 입니다(이러한 개념 때문에 manifold는 위상수학(topology)에 등장합니다).
그리고 manifold learning은 이러한 manifold를 잘 찾는 것을 목표로 하는 학습입니다.
그렇다면 manifold learning이 왜 필요할까요? 고차원의 manifold를 잘 찾아낸다면, 고차원의 manifold를 저차원으로 압축했을 때 각 데이터들의 특징을 유지하면서 압축이 가능하기 때문입니다.
아래 예시를 보면 고차원(이미지의 784차원을 그림으로 나타낼 수 없어서 3차원으로 대체)에서 모든 데이터들의 오차를 최소로하는 manifold를 찾았다면, 이 manifold를 바탕으로 저차원(그림에서 2차원)으로 효과적으로 압축할 수 있기 때문입니다.
그리고 이렇게 데이터의 특징을 잘 추출하여 압축한 저차원의 데이터가 바로 위에서 언급한 각 데이터들의 latent variable, 즉 잠재 변수라고 판단할 수 있습니다.
위의 그림을 예시로 들자면, 784차원으로 표현할 수 있는 데이터의 manifold를 잘 찾아서 4차원의 잠재 변수로 나타내는 것이 바로 autoencoder가 하는 역할입니다.
그리고 잠재 변수의 차원이 가진 데이터의 수보다 너무 높으면 데이터의 공통된 특징을 찾지 못하고 압축된 데이터의 특징 분포가 중구난방으로 퍼질 수 있으며, 차원이 너무 작게 되면 정보 손실이 일어나서 각 데이터의 특징이 희미할 수 있습니다.
따라서 적당한 차원을 가진 잠재 변수를 찾아 각 데이터의 특징으로 사용하는 것이 중요합니다.
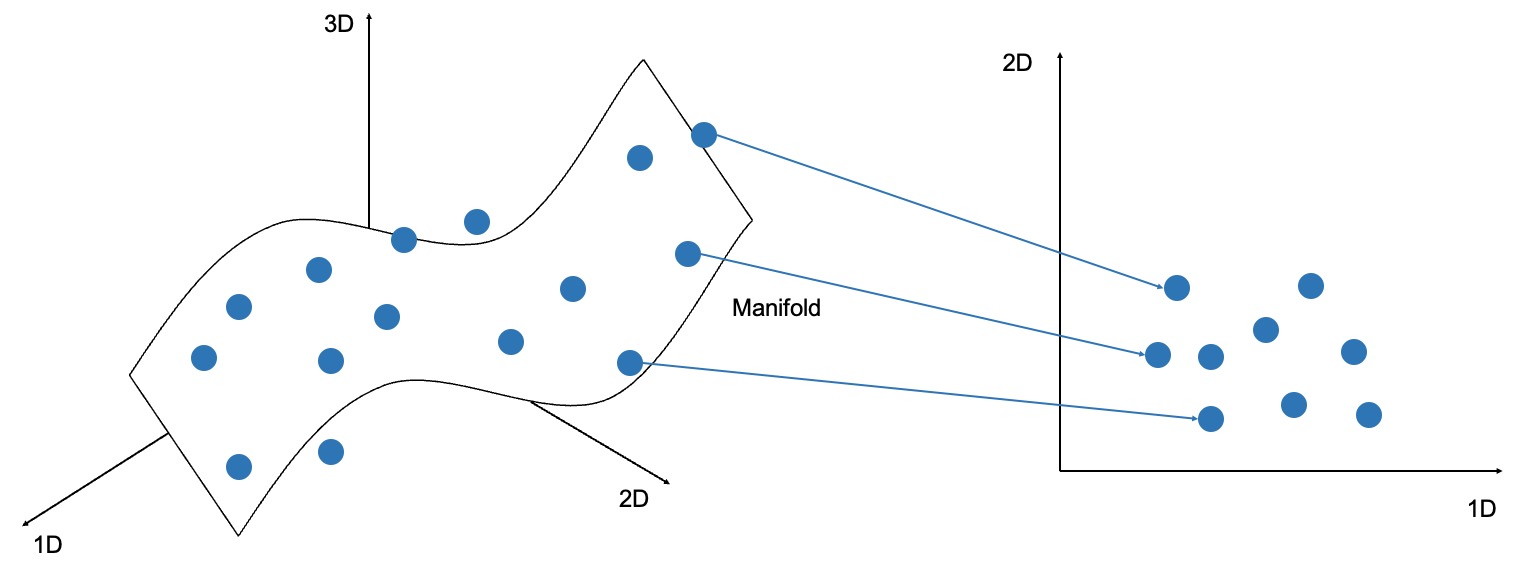
차원 축소(3D → 2D)
추가로 데이터를 잘 아우르는 manifold를 찾았다면, 이론적으로 딥러닝 모델을 학습하기 위해 구축한 데이터에 존재하지 않는 새로운 데이터를 형성할 수 있다는 의미도 될 수 있습니다.
예를 들어 여자 사진의 고차원의 특징을 고차원 평면에 점을 찍을 수 있을 것입니다.
이렇게 찍힌 점들을 활용하여 각 점들을 잘 아우르는 manifold를(부분 공간)을 예측 할 수 있을 것입니다(e.g. (2, 4), (3, 6)이 존재하는 선은 우리가 y=2x라고 예측 가능함).
만약 우리가 점들을 잘 아우르는 subspace, 즉 manifold를 찾았다면, 학습 데이터에 존재하지 않았던 새로운 점을 추출하여(sampling) 데이터에 없던 새로운 여자 사진을 생성할 수 있을 것입니다(e.g. y=2x로 예측한 선에서 (4, 8)의 데이터를 추출 가능).
이는 우리가 가정한 특정 분포에서 새롭게 데이터를 생성하는 VAE (Variational Autoencoder)와 연관이 있으며, VAE는 본 글에서 설명하는 autoencoder와 이름은 비슷하지만 전혀 다른 특징을 가진 모델입니다.
이에 관해서는 아래에 추가로 설명하도록 하겠습니다.
Autoencoder ”
위에서 manifold learning은 고차원의 데이터를 각 데이터의 의미있는 특징을 추출하여 저차원으로 압축시키는 학습이라고 설명하였습니다. 쉽게 말하면 그냥 고차원의 데이터를 저차원으로 잘 만드는 것이라고 생각하면 되겠습니다.
여기서 유추할 수 있듯이, manifold learning의 가장 큰 역할 중 하나가 바로 차원 축소(dimension reduction)입니다.
그럼 차원 축소 말고도 autoencoder의 다른 역할은 무엇이 있을까요?
- 차원 축소(Dimension reduction, Data compression)
- 의미 있는 특징 추출(Feature extaction)
- 데이터 가시화(Data visualization)
- 차원의 저주 해결(Curse of dimensionality)
차원의 저주 해결
그럼 4번의 차원의 저주 해결이란 무엇일까요? 우리가 극단적으로 생각했을 때 위에 예시로 들었던 사람 사진의 데이터가 10장밖에 없다고 가정해봅시다. 각 이미지의 데이터는 784차원(28×28)이며, 10장밖에 없는 데이터로 여자, 남자를 구분해야한다면, 모델의 성능이 잘 안나올 수 있습니다. 왜냐하면 각 데이터가 너무나도 큰 차원을 가지기 때문에 10장만으로 784차원 중 각 차원이 무엇을 나타내는지, 혹은 784개의 특징들의 순서/조합이 어떤 것을 의미하는지 표본이 적기 때문에 모델은 알기 어려울 것입니다(좀 더 자세히 말하자면 모델이 크면 10장의 데이터는 높은 정확도로 여자인지 남자인지 구분을 잘 할 것이지만, 새로운 데이터가 들어왔을 때 여자/남자를 구분하는 정확도가 떨어질 것입니다. 이것이 바로 모델이 overfitting (과적합)되었다고 표현합니다). 이런 경우를 차원의 저주(Curse of Dimensionality)라고 표현합니다. 즉 '데이터의 차원이 높아질 수록 데이터의 양은 기하급수적으로 많아져야한다'라는 뜻입니다.
즉 우리가 분석하고싶은 데이터가 고차원인데 그 수가 적다면 의미있는 학습을 못합니다. 이러한 문제점을 해결하기 위해서는 데이터 수를 늘리거나 차원을 줄이는 것입니다. 만약 우리가 데이터 수를 늘리기에 한계가 있을 때, 차원의 저주 문제를 해결하기 위해 autoencoder를 사용할 수 있는 것입니다. 즉 autoencoder를 사용하여 고차원의 데이터에서 저차원의 잠재 변수를 추출할 수 있고, 각각의 잠재 변수는 각각의 데이터를 대표할 수 있다는 의미가 됩니다. 따라서 기존 고차원의 데이터를 그대로 분석에 사용하는 것 보다 저차원으로 잘 압축된 잠재 변수를 각각의 데이터 대신에 분석에 사용해도 괜찮다는 것과 같은 뜻입니다. 아래 그림은 차원의 저주를 해결하면 고차원의 적은 데이터로 볼 수 없었던 의미있는 특징들이 저차원으로 낮췄을 때 보이는 것을 보여주는 예시입니다. 고차원에서 데이터의 수가 적어 공간 대비 밀도가 낮았던 데이터들이 저차원이 되면서 밀도가 높아지는 효과를 얻는 것이지요.

차원의 저주를 고차원의 데이터로 저차원으로 낮추어서 해결
의미 있는 특징 추출
이제 autoencoder를 사용하는 대부분의 이유를 차지하는 2번 역할인 특징 추출에 관해 좀 더 자세히 이야기 해보도록 하겠습니다.
아래에서 A1, A2, B는 이미지가 압축된 잠재 변수이며 데이터의 manifold 위에 존재하고, C는 manifold 위에 존재하지 않는 데이터라고 가정해봅시다.
사실 유클리드 거리(Euclidean distance)는 B-A2, A1-A2보다 B-C, A1-C가 더 가깝습니다. 하지만 C의 데이터를 추출해보면 그림과 같이 B와 A1 그림을 단순 합성한 의미없는 그림이 되어버립니다.
그러나 C와 다르게 A2는 다른 점들과의 유클리드 거리는 더 멀지만 우리가 골프 행위의 순서를 생각해보면 더 합리적인 그림이 나오는 것을 확인할 수 있습니다.
따라서 autoencoder를 통해 추출된 특징은 단순히 비슷한 것끼리 거리만 가깝게 학습 되는 것이 아니라, 데이터의 순서와 같은 의미론적인 부분도 학습을 잘해야한다는 것을 알 수 있습니다.
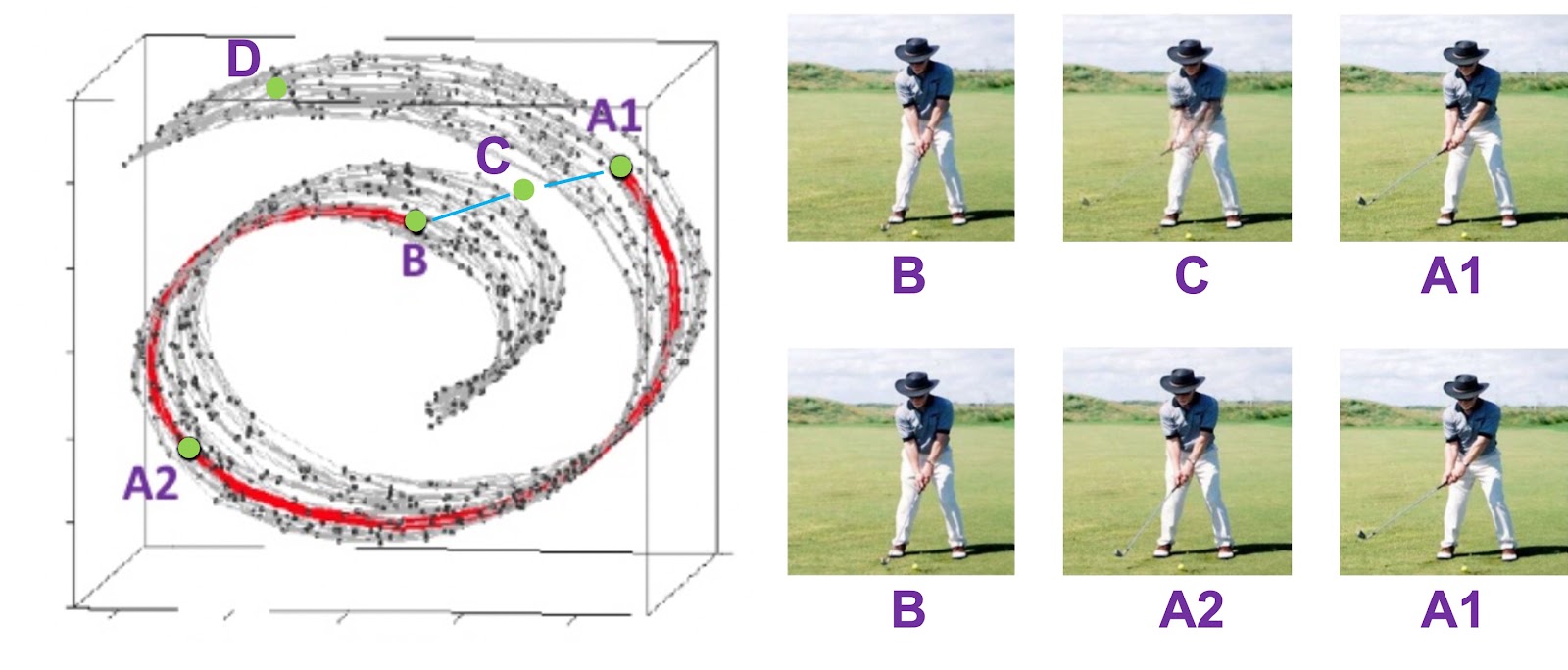
특징 추출의 예시, 출처: 오토인코더의 모든 것
그리고 이제 위의 그림의 D를 생각해보도록 합시다. D는 분명 manifold 위에 존재하지만, 우리의 학습 데이터에는 없는 이미지라 가정을 합시다.
우리는 학습 데이터에 없는 이미지지만 manifold의 순서를 생각해본다면, 골프공을 치고 난 후의 모습이라는 것을 예측할 수 있을 것입니다.
그럼 우리가 D의 값을 추출하여 그림을 그릴 수 있을까요? 아쉽게도 우리가 명시적으로 압축된 데이터(잠재 변수)를 포함하는 manifold (subspace) 식을 구할 수 없다면 D 지점의 데이터를 추출할 수 없을 것입니다.
그리고 여기서 설명하는 autoencoder는 명시적으로 manifold의 식을 구하는 것이 아니라서, autoencoder 목적은 '적어도 학습 데이터에 존재하는 데이터만 특징 추출을 잘하자!'로 국한됩니다.
따라서 위에서 잠깐 언급한 VAE는 이러한 국한된 목적을 넘어서 '명시적으로 잠재 변수가 존재하는 manifold의 분포를 가정하고 그 분포 내에서 데이터를 추출하여 학습 데이터에 없는 데이터를 생성하자!'는 목적을 가지게 됩니다.
- Autoencoder의 목적: 적어도 학습 데이터 내에 있는 것만을 가지고 다른 데이터가 들어왔을 때 특징만(잠재 변수) 잘 잡아내도록 학습하자
- VAE의 목적: 잠재 변수가 존재하는 manifold를 명시적으로 가정하고, 가정한 manifold 분포 내에서 학습 데이터에 없는 데이터를 생성해보자
데이터 가시화
그럼 VAE는 잠시 잊고, autoencoder가 잘 학습되어 의미있는 잠재 변수를 잘 추출한다는 것은 어떻게 증명할 수 있을까요?
증명할 수 있는 방법은 바로 데이터를 차원 축소하여 추출한 잠재 변수를 가시화 해보는 것뿐입니다.
잠재 변수를 우리가 볼 수 있는 2, 3차원으로 그려보았을 때 비슷한 것끼리 군집이 잘 된다면, 특징 추출해주는 autoencoder 모델은 잘 학습 되었다고 판단할 수 있겠지요.
아래 그림은 실제 784차원의 MNIST 데이터를 저차원의 잠재 변수로 만든 후, t-SNE (t-distributed Stochastic Neighbor Embedding)라는 또다른 manifold learning을 통해 2차원의 데이터로 가시화한 모습입니다.
Manifold Learning에는 이렇게 autoencoder뿐 아니라 t-SNE, UMAP (Uniform Manifold Approximation & Projection) 등 다양한 기법들이 있습니다.
그리고 데이터의 분포를 가시화하기 위해서는 이들을 섞어서 쓸 수도 있습니다(e.g. 잠재 변수는 autoencoder로 추출한 후, 잠재 변수를 다시 더 작은 차원인 2, 3차원으로 t-SNE 등으로 압축하여 가시화).
이 글 마지막에는 manifold learning의 종류를 간단히 알아보고 t-SNE와 UMAP은 다음 포스팅에서 더 자세히 알아보도록 하겠습니다.

t-SNE를 이용한 MNIST 데이터의 잠재 변수 가시화
Architecture of Autoencoder ”
이제 autoencoder의 구조를 알아볼 차례입니다.
아래 그림처럼 autoencoder의 전체적인 구조는 원래 데이터를 잠재 변수 혹은 데이터 특징으로 압축하는 인코더 부분과 압축된 잠재 변수를 다시 원래의 데이터로 복구하는 디코더 부분으로 이루어져 있습니다.
위에서 보았던 예시를 기준으로 부가적인 설명을 해보겠습니다. 먼저 28×28 크기의 이미지는 모두 한 줄로 이어붙여서 최종적으로 784차원의 벡터로 변환할 수 있습니다.
이렇게 변환된 이미지가 여자/남자 각각 한 장씩 있으므로 데이터는 총 2×784의 크기를 같습니다(2×28×28 → 2×784).
그리고 2×784의 크기를 가지는 데이터를 \(x\)라고 표현합니다.
그리고 사진에서 볼 수 있듯이 \(x\)를 인코더에 넣어서 4차원의 잠재 변수로 압축합니다. 이렇게 구한 잠재 변수를 보통 \(z\)로 표현합니다.
그리고 잠재 변수 \(z\)는 데이터 특징, code, representation 등으로 다양하게 부릅니다.
이렇게 압축된 잠재 변수를 다시 디코더로 넣어서 확장시켜 원래의 크기인 2×784의 데이터로 복구합니다. 이를 \(x'\)라 표현합니다.
이렇게 데이터를 압축했다가 다시 확장시켜서 나온 결과인 \(x'\)와 원래 데이터인 \(x\)의 오차를 구하면서 모델은 학습을 하게 됩니다.
이 둘의 손실 즉 loss는 mean squared error (MSE) loss 함수를 사용하여 구합니다. 아래 식은 MSE loss를 나타낸 식입니다.
\(N\)은 전체 데이터의 개수를 의미하기 때문에 모든 데이터의 mean squared 값의 평균을 구하기 위해 나누어준 것입니다.
\[MSE\,Loss = \frac{1}{N}\sum_{i=1}^{N} (x_i - x'_i)^2 \]
이렇게 원래 차원보다 작아진 잠재 변수는 어쩔 수 없이 원래 데이터 \(x\)가 가지고 있는 정보량보다 적을 수밖에 없습니다(차원이 현저히 작기 때문).
디코더는 이렇게 원래 데이터 \(x\) 대비 정보 손실이 일어난 잠재 변수만을 가지고 최대한 원래 데이터와 비슷하게 \(x'\)를 \(x\)로 복구해야 합니다.
이러한 과정에서 인코더는 디코더에게 넘겨줄 잠재 변수의 정보를 최대화 하는 방향으로 학습하게 되며, 의미있는 잠재 변수를 만들어내게 됩니다.

Autoencoder (오토인코더)의 구조
지금부터는 간단한 수식과 함께 autoencoder를 정의해보겠습니다.
사실 실제로 사용하는 데 있어서 수식이 그리 중요하지 않으니, 관심이 없으신 분들은 넘어가셔도 무방합니다.
하지만 딥러닝과 관련된 논문들을 읽거나, 조금 더 깊게 들어가고싶다면 수식에 익숙해지는 것이 매우 중요하다고 생각합니다.
지금 볼 수식은 아주 조금만 이해를 하려고 노력한다면 어렵지 않은 수식이니 참고하시기 바랍니다.
먼저 원래 데이터 \(x\)와 복구된 결과를 나타내는 \(x'\)는 \(d\)차원을 가집니다(위 그림 예시에서는 \(d\)는 784차원).
따라서 아래와 같이 표현할 수 있습니다.
그리고 이중에서 \(x\)는 인코더 \(f_\theta\)를 통과합니다. 이 인코더는 가중치(weight)를 포함하고 있는 모델이며, 가중치 \(W\)와 bias \(b\)를 거칩니다. 이렇게 인코더를 거친 \(x\)는 잠재 변수 \(z\)가 되며 이러한 과정은 아래와 같이 쓸 수 있습니다. 아래 식은 인코더의 layer가 하나라고 가정했을 때를 나타냅니다.
이렇게 구한 \(z\)는 디코더 \(g_\phi\)를 통과하여 \(x'\)가 됩니다. 이 디코더 역시 가중치와 bias를 가지고 있으므로 아래와 같이 쓸 수 있습니다. 또한 아래 식은 인코더와 동일하게 디코더의 layer가 하나라고 가정했을 때를 나타냅니다.
그럼 여기서 잠시 위의 인코더/디코더와 다르게 각각의 layer가 한 개 이상이라면 어떻게 될까요? 위의 autoencoder 그림의 구조에서는 \(x\)에서 바로 잠재 변수로 압축되었지만 아래 그림처럼 하나 이상의 hidden layer를 거친 후, 잠재 변수로 압축될 수 있습니다. 그럼 아래 그림처럼 인코더 \(f_\theta\)와 디코더 \(g_\phi\)가 두 개의 hidden layer를 가지고 있다고 가정을 한다면 이는 아래와 같이 쓸 수 있을 것입니다. 그리고 이를 응용한다면 multiple layers를 가진 모델에 대해서도 수학적으로 나타낼 수 있을 것입니다.

Autoencoder (오토인코더)의 구조
다시 본론으로 돌아와서 이제 이렇게 구한 \(x\)와 \(x'\)는 MSE loss 함수에 들어가게 됩니다. 위에서 잠깐 나온 MSE loss 식을 가져와셔 \(x\)와 \(x'\)에 대해 표현하면 아래와 같습니다.
\[MSE\,Loss: L(x, x') = \frac{1}{N}\sum_{i=1}^{N} (x_i - x'_i)^2 \]
이렇듯 autoencoder의 수식은 직관적이기 때문에 그리 어렵지 않습니다.
지금까지 살펴보았듯이 vanilla autoencoder의 가장 기본적인 구조는 위에서 설명한 것처럼 압축과 팽창을 하는 구조로 이루어져 있습니다. 최종적으로 autoencoder가 어떻게 데이터의 특징을 잘 잡아서 의미있는 잠재 변수를 추출하게 되는지 정리하자면 아래와 같습니다.
- 잠재 변수는 원래의 고차원 데이터에서 저차원으로 압축된 데이터이다.
- 잠재 변수는 저차원으로 압축이 되었기 때문에 원래의 데이터에 비해 정보 손실이 일어난다.
- 디코터는 저차원으로 압축되어 정보 손실이 일어난 잠재 변수를 바탕으로 각 잠재 변수에 해당하는 원래의 데이터로 복구해야한다.
- 인코더는 디코더를 위해서 원래 데이터에서 최대한 의미있는 잠재 변수(특징)을 추출하는 방향으로 학습된다.
- 따라서 autoencoder는 데이터에서 의미있는 특징, 잠재 변수를 추출할 수 있게 된다.
위에서 vanilla autoencoder라고 잠깐 언급하였습니다. Vanilla는 다들 아시다시피 모델의 가장 기본적인 형태임을 의미합니다.
그렇다면 위의 구조가 아닌 다른 구조를 가진 autoencoder가 존재한다는 의미인데, 어떤 종류의 autoencoder가 있는지는 아래에서 살펴보도록 하겠습니다.
이와 더불어 autoencoder 뿐만이 아닌, manifold learning을 위한 다른 모델들은 어떤 것들이 있는지 간단하게 알아보도록 하겠습니다.
Models for Manifold Learning & Other Autoencoders ”
Manifold Learning을 위한 모델 종류
먼저 manifold learning을 위해 사용되는 모델들을 알아보겠습니다.
지금 소개할 모델들은 바로 위에서 언급한 autoencoder의 역할과 비슷한 역할을 하기 위해 사용되는 모델들입니다(차원 축소, 의미 있는 특징 추출, 데이터 가시화, 차원의 저주 해결).
- 선형 변환(Linear Transformation)
- 주성분 분석(Principal Component Analysis, PCA)
- 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)
- 비선형 변환(Non-linear Transformation)
- 오토인코더(Autoencoder, AE)
- t-SNE (t-distributed Stochastic Neighbor Embedding)
- UMAP (Uniform Manifold Approximation & Projection)
- Isomap
- LLE (Locally-linear Embedding)
- 자기조직화 지도(Self-organizing Map, SOM)
PCA는 기존 변수를 선형 조합하여 새로운 변수를 만들어 내는 분산 기반 선형 변환 기법입니다. 각 데이터가 차원 축소를 했을 때 최대한 겹치지 않는 eigenvector를 구한 후, 그 벡터에 맞춰서 선형 변환하는 것입니다. 즉 분산이 커지는 방향으로 학습을 하는 것이지요. PCA를 좀 더 자세히 공부해보시면 공분산과 eigenvector의 내용이 나옵니다. 본 글은 PCA에 대한 글이 아니므로 자세한 부분은 넘어가도록 하겠습니다.
LDA는 토픽 모델링(Topic Modeling) 기법 중 하나입니다. 토픽 모델링은 문서들 속에서 어떠한 토픽이 존재하는지 찾아내는 과정입니다. 토픽 모델링은 실제로 고객을 대상으로하는 서비스와 검색 엔진에 중요하게 사용되는 개념입니다. LDA는 문서 속에 여러 토픽들이 들어있다고 가정을 합니다(e.g. "나는 상추와 배추를 직접 재배해서 먹어"라는 문서에는 일상이라는 토픽이 30 %, 식물이라는 토픽이 70 %존재함). 그리고 그 문서의 토픽을 결정하는 데 단어가 기여를 한다고 가정합니다. 그리고 LDA를 통해 문서가 만들어지게 된 과정을 예측하고 분석하여 토픽을 찾아줍니다.
t-SNE는 고차원에서의 데이터간 거리와 저차원으로 임베딩 후 데이터간 거리를 유사하게 유지하면서 차원 축소하는 비선형 변환입니다. 실제로 고차원(e.g. 256차원) 데이터에서 저차원(e.g 32차원)으로 잠재 변수를 학습하는 데 autoencoder를 사용한 후, 이 잠재 변수를 다시 사람이 볼 수 있는 2, 3차원으로 압축하는 데 t-SNE가 많이 사용됩니다. 여기서 우리가 알 수 있는 사실은 우리가 꼭 하나의 manifold learning model를 사용할 필요는 없다는 것입니다. 이렇게 autoencoder와 t-SNE를 같이 조합하여 사용하여도 무방합니다.
UMAP은 고차원에서의 그래프와 저차원에서의 그래프를 유사하게 최적화하여 변환하는 기법입니다. t-SNE와 UMAP은 다음 포스팅에서 더 자세히 다뤄볼 예정입니다.
Isomap은 모든 데이터에 대해 각각의 k개의 이웃한 정보와 graph를 구성합니다. 그리고 각 데이터 간의 거리를 graph의 최단 거리로 정의합니다. 그리고 각 데이터간의 거리 정보를 보존하면서 차원을 축소하는 기법입니다. 즉 아래 그림에서처럼 B와 A1의 직선 거리를 두 데이터간의 거리로 정의하는 것이 아니라, B와 A1을 잇는 빨간 선을 두 데이터간의 거리로 정의하여 학습을 하는 것이지요.

특징 추출의 예시, 출처: 오토인코더의 모든 것
LLE는 모든 데이터에 대해 각각 가장 가까운 이웃 k개를 찾습니다. 이 기법의 특징은 이웃한 데이터, 즉 locality만을 고려한다는 특징이 있습니다.
따라서 고차원에서의 한 데이터와 각 이웃한 데이터가 특정 weight (가중치)와 선형 결합이 될 것이라 가정을 합니다.
그리고 고차원에서 학습한 weight를 고정시킨 후, 저차원으로 내려와서 고정된 weight를 이용하여 저차원에 매핑 될 공간을 학습하는 방식으로 이루어집니다.
SOM는 사람이 볼 수 있는 2, 3차원 격자에 각 고차원 벡터 값들을 대응시켜 neural network (NN)과 유사한 방식으로 결과 도출하는 방법입니다.
Autoencoder의 종류
Autoencoder의 유명한 모델로는 아래의 예시가 있습니다.
- Vanilla Autoencoder (AE)
- Linear Autoencoder
- Denoising Autoencoder (DAE)
- Sparse Autoencoder
- Stacking Autoencoder
2. Linear autoencoder는 vanilla autoencoder와 구조가 거의 유사합니다. 그럼 다른 부분은 무엇일까요? 딥러닝 모델들은 단순히 weight라고 불리는 가중치 행렬을 데이터에 곱해주는 것인데, 왜 우리는 딥러닝 모델들을 비선형 즉 non-linear하다고 표현을 할까요? 바로 ReLU (Rectified Linear Unit), GELU (Gaussian Error Linear Unit)과 같은 비선형성을 추가해주는 activation function을 거치기 때문이죠. 바로 위에서 언급한 vanilla autoencoder도 이러한 activation function이 추가되어 있기에 비선형적 변환이라고 표현합니다. 하지만 여기서 설명하는 linear autoencoder는 이러한 activation function이 들어가있지 않은 구조입니다. 따라서 linear autoencoder로 차원을 축소하거나, 특징을 추출한 결과를 보면 PCA와 유사한 manifold를 학습한다고 합니다.

ReLU, GELU 활성화 함수(Activation Function)
3. Denoising AE (DAE)는 autoencoder에 들어가는 데이터를 망가뜨린 후 모델에 넣는 방법입니다.
이를 corrupted 된 데이터를 넣는다고 표현합니다. DAE의 구조는 아래 그림과 같습니다. 구조는 vanilla autoencoder와 동일하지만 중간에 데이터가 망가지는 부분이 추가되는 것을 확인할 수 있습니다.

DAE의 학습 방법
DAE를 사용할 때는 loss function을 주의 깊게 봐야 합니다. 분명 모델에 들어가는 것은 노이즈가 낀 손상된 이미지인데, 정작 loss는 손상되기 이전의 원래 이미지와 나온 결과를 가지고 계산합니다.
\(x\)를 원래 이미지, \(\widetilde{x}\)를 손상된 이미지, \(x'\)가 복구된 이미지라고 했을 때 DAE의 loss function은 아래와 같습니다.
즉 vanilla autoencoder와 동일하게 \(x\)와 \(x'\)를 가지고 MSE loss를 구하게 되는 것이지요.
그렇다면 도대체 노이즈는 어떤 노이즈를 주게 될까요? 노이즈는 보통 인풋으로 들어오는 데이터 크기와 동일한 Gaussian noise를 주게 됩니다. 혹은 때때로 dropout을 추가하는 것도 이러한 효과를 낼 수 있습니다.
데이터에 노이즈를 추가하는데 모델의 성능에는 과연 문제가 없을까요? 물론 노이즈를 데이터를 분간할 수 없을 정도로 주면은 그것은 문제가 되겠지만, 작은 노이즈를 주는 것은 higher level representation에 큰 영향을 주지 않습니다(e.g. raw image). 오히려 손상된 이미지만을 보고 모델은 손상되기 이전의 이미지로 복구해야하니, 더 의미 있는 잠재 변수를 학습하게 됩니다.
4. Sparse AE는 인코더의 결과로 나온 잠재 변수에 sparsity, 즉 희소성을 강제하는 것입니다. 기존의 autoencoder의 잠재 변수는 인코딩 과정에서 모든 데이터를 참조하여 구성됩니다. 하지만 sparse autoencoder는 잠재 변수에서 활성화 되는 뉴런의 수를 제한하여, 모든 잠재 변수를 디코더가 참조하지 못하도록 강제하는 기법입니다. 매번 학습이 될 때마다 활성화 되는 뉴런이 랜덤으로 바뀌면서, 디코더는 다른 조합의 잠재 변수를 참조하게 됩니다. 우리가 정답을 아는 상황에서 정답을 다시 복구하는 것보다, 정답을 완전히 다 모르는 상태에서 더듬더듬 조금씩 만져가며 정답을 완성해가는 과정이 더 의미있는 잠재 변수가 나오며 robust한 모델이 학습된다는 효과를 기대하는 것이지요. 아래 그림은 sparse autoencoder가 매 학습 iteration마다 다른 잠재 변수의 뉴런이 활성화 되는 모습을 묘사한 것입니다.

Sparse Autoencoder
그렇다면 어떻게 잠재 변수에 활성화 되는 뉴런의 수를 조절할 수 있을까요? 바로 loss function에 sparsity를 강제하는 term을 추가하여 학습하게 됩니다.
위의 식에서 \(L(x, x')\)는 이때까지 많이 봐왔던 디코더에서 나온 결과를 원래 데이터로 복구하는 MSE term인 것을 알 수 있습니다. 그런데 sparse autoencoder에서는 \(\Omega(z)\) term이 추가된 것을 볼 수 있습니다. \(\Omega(z)\)가 바로 sparsity를 강제하는 부분입니다. 이 \(\Omega(z)\) 부분의 식은 보통 두 가지의 방법을 사용하여 sparsity를 강제합니다.
-
\(\Omega(z)\,=\,\sum_{i}KL(\rho||\hat{\rho}_i)\)
\((\rho:\,average\,of\,target\,Bernoulli\,distribution\), \(\hat{\rho}_i:\,average\,activation\,of\,z)\) - \(\Omega(z)\,=\,\lambda\sum_{i}|z_i|\)
2번 식이 의미하는 것은 바로 L1 regularization (L1 규제)를 사용하는 것입니다. L1 regularization을 사용하게 되면 L1 norm의 특성으로 인하여 기울기가 0이 발생하는 경우도 발생하고, 해당 잠재 변수가 비활성화되는 효과를 바란 것입니다.
5. Stacking AE는 과거 Xavier 초기화 방법 등 모델의 가중치 초기화 방법이 없을 때 종종 사용한 방법입니다. 먼저 아래 그림을 보면 hidden layer가 네 종류 있는 것을 확인할 수 있습니다. Stacked autoencoder는 차례로 각각 hidden layer의 해당하는 가중치들을 학습하는 방식입니다. 첫 번째로 아래 그림에서 'input → 1000 hidden layer → input'과 같은 오토인코더의 구조를 이용하여 첫 번째 hidden layer의 가중치를 학습합니다.

Stacked Autoencoder, 출처: http://speech.ee.ntu.edu.tw/course/ML_2017/Lecture/auto.pptx
두 번째도 hidden layer의 가중치도 위의 방법과 동일하게 가중치가 정해진 첫 번째 hidden layer를 통과한 결과를 바탕으로 학습합니다.

Stacked Autoencoder, 출처: http://speech.ee.ntu.edu.tw/course/ML_2017/Lecture/auto.pptx
세 번째 hidden layer도 동일합니다.

Stacked Autoencoder, 출처: http://speech.ee.ntu.edu.tw/course/ML_2017/Lecture/auto.pptx
이런식으로 계속 진행하다보면 마지막 hidden layer만 빼고 다 학습이 가능하며, 마지막 hidden layer는 랜덤으로 초기화 합니다.

Stacked Autoencoder, 출처: http://speech.ee.ntu.edu.tw/course/ML_2017/Lecture/auto.pptx
다시 정리해보자면 stacked autoencoder는 autoencoder 기법을 부분적으로 여러번 사용하는 것입니다. 따라서 이름도 stacked autoencoder인 것이지요.
그리고 번외로 stacked denoising autoencoder (SDAE)라는 모델도 존재하는데, 이는 위에서 설명한 DAE기법을 stacked autoencoder에 적용하는 방법이라고 보시면 무방할 것입니다.
Applications of Autoencoder ”
그럼 autoencoder는 어디에 쓰일까요? 지금까지 예시는 모두 이미지로 국한된 예시들이었습니다.
그리고 언뜻 생각해보면 적용할 수 있는 분야가 이미지 분야밖에 없는듯 합니다.
하지만 곰곰이 생각해보면 이미지도 모두 숫자로 구성된 벡터입니다.
그럼 autoencoder는 숫자로 나타낼 수 있는 모든 데이터에 적용할 수 있다는 뜻이 됩니다.
즉 이미지 뿐 아니라, 이미지가 아닌 어느 숫자로 된 데이터, 자연어 데이터, 음성 데이터에도 모두 autoencoder를 적용할 수 있는 것이지요.
그리고 위에서 우리가 다양한 autoencoder의 종류를 보긴 하였지만, 모델의 레이어가 모두 linear hidden layer 였습니다.
그렇다면 우리는 CNN에서 사용되는 convolution layer, RNN 계열에서 사용되는 recurrent layer는 사용될 수 없는 것일까요?
그렇게 생각하면 오산입니다.
예를 들어 차원을 압축하는 인코더 부분에서는 convolutional layer를 사용하고, 압축 된 잠재 변수를 다시 확장시키는 디코더에서는 데이터를 interpolate 하고 convolutional layer를 사용하거나 transposed convolutional layer를 사용할 수도 있습니다.
그리고 자연어 처리 분야(NLP)의 번역 모델의 초기 형태인 seq2seq (sequence to sequence) 모델을 응용하여 autoencoder를 구현할 수도 있습니다.
아래 그림은 convolutional autoencoder (CAE)와 t-SNE를 같이 조합하여 사용하는 모습을 나타낸 그림입니다.
위에서 t-SNE 이야기를 할 때 말했던 것처럼 꼭 하나의 manifold learning model를 사용해야하는 것은 아닙니다.
아래처럼 두 가지의 모델을 같이 조합하여 사용해도 되는 것이지요.

Convolutional Autoencoder와 t-SNE의 사용
또한 나중에 글을 작성할테지만 transformer와 같은 구조에서도 autoencoder는 나올 수 있습니다.
실제로 transformer 구조와 거의 유사한 모델 구조를 지닌 autoencoder가 바로 비교적 최근에 나온 BART (Bidirectional and Auto-Regressive Transformers) 모델입니다
(BART 논문에서는 BERT+GPT 구조라고 언급). 이 모델은 단순한 linear layer를 사용한 모델은 아니지만, 위에서 설명한 DAE의 기법을 추가한 모델입니다.
즉 transformer 형태의 모델을 사용하였지만, 우리가 알고있는 DAE 방법도 섞어서 사용한 모델이 바로 BART인 것이죠(자연어에서 noise를 주는 방법은 단어를 마스킹, 문장의 순서를 섞는 등의 방법이 존재).

BART 모델 구조, 출처: BART paper
마지막으로 글을 마치면서 위의 이야기로 우리가 알 수 있는 가장 중요한 사실은 바로 autoencoder의 개념만 알면 구조, 학습 방법에 제약 받지 않고 다양한 형태의 모델이 나올 수 있다는 것입니다.
그리고 이러한 사실은 우리가 꼭 이미지에 대해서만 적용할 수 있는 것이 아니라, 자연어, 음성 등 우리가 분석하고자 하는 모든 데이터에 대해 적용할 수 있다는 또다른 사실로 이어지죠.
이제 오토인코더에 관한 글은 여기서 마무리 하고 다음에는 앞서 얘기한 t-SNE와 UMAP에 대해 이야기 해보도록 하겠습니다.


