딥러닝 이야기 / Manifold Learning / 2. t-SNE, UMAP

작성일: 2022.02.20
시작하기 앞서 틀린 부분이 있을 수 있으니, 틀린 부분이 있다면 지적해주시면 감사하겠습니다.
Manifold learning의 이야기 중 이전 글은 latent variable (잠재 변수)부터 시작하여 manifold와 autoencoder (오토인코더)에 대해 설명하였습니다.
그리고 마지막에는 autoencoder의 모델의 종류와 더불어 manifold learning을 위한 모델의 종류도 살펴보았는데 그중에 유명한 모델이 바로 t-SNE와 UMAP입니다.
이전 글에서 이 두가지의 모델을 살짝 언급하고 넘어갔었는데, 오늘 이야기의 주제가 바로 t-SNE와 UMAP입니다.
그리고 manifold learning과 autoencoder에 대한 글은 여기를 참고하시기 바랍니다.
오늘의 컨텐츠입니다.
- t-SNE
- 정규분포
- t 분포 (스튜던트 t 분포)
- t-SNE
- UMAP
- UMAP
t-SNE
t-SNE는 t-distributed Stochastic Neighbor Embedding의 약자로써 이때 t-distributed는 t 분포를 의미합니다. 따라서 t-SNE에 대해 알아보기 전에 t 분포에 대해 먼저 집고 넘어가야 합니다. 그리고 정규분포(normal distribution)에 대한 개념을 이해한다면, t 분포에 대해 이해를 더 수월하게 할 수 있으므로 아주 간단하게 정규분포에 대해 집고 넘어가도록 하겠습니다.
Normal Distribution ”
정규분포에 대해 설명하기에 앞서 기초적인 확률과 통계의 개념이 필요한 것은 사실입니다.
다만 모든 것을 이해 하지 않아도 충분하고, 아래에 있는 예시를 통해 느낌만 알아도 t-SNE를 이해하는 데 도움이 될 수 있습니다.
먼저 정규분포 혹은 가우스 분포라고 하는 것은 연속 확률 분포 중 하나입니다.
정규분포는 수집된 자료의 분포를 근사하는 데에 자주 사용되며, 이것은 중심 극한 정리(Central Limit Theorem, CLT)에 의하여 독립적인 확률 변수들의 평균은 정규분포에 가까워지는 성질이 있기 때문입니다.
그리고 중심 극한 정리는 확률 변수 n개의 표본 평균은 n이 적당히 크다면 정규분포를 따른다는 정리입니다. 중심 극한 정리에 대한 자세한 부분은 여기서 다루지 않을 예정입니다.
다시 본론으로 돌아와서, 정규분포를 결정하는 요인은 두 가지가 있습니다. 바로 평균(\(\mu\), mean)과 표준편차(\(\sigma\), standard deviation)입니다.
즉 정규분포의 형태는 평균과 표준편차에 따라 결정되고, 그때의 정규분포는 아래와 같이 씁니다.

평균과 표준펀차에 따른 정규분포 차이, 출차: 위키피디아
사실 여기까지 보면 실제 실생활에서 발생할 수 있는 어떠한 확률적 사건 혹은 어떠한 예시가 정규분포를 따르는지 궁금할 것입니다.
그래서 "주사위 600번 던졌을 때 1이 나오는 횟수 세기"라는 실험을 10번, 100번, 1,000번, 10,000번을 반복한 결과를 보여드리겠습니다.
일반적으로 주사위 던지기를 생각했을 때 1이 나오는 횟수가 정규분포를 따른다는 것이 상상이 가지 않으실 겁니다. 그리고 우리는 상식적으로 600번 던졌을 때 1이 나올 횟수가 100에 가까울 것이라고 추측할 수 있습니다(600의 1/6).
아래의 예시는 주사위 600번 던지는 실험을 10번 했을 때의 결과입니다. 그래프에서 빨간색이 주사위 600번 던졌을 때 우리가 이론적으로 생각할 수 있는 정규분포의 모습입니다.
이 빨간색의 분포가 어떻게 나왔는지에 대해서는 조금 뒤에 설명을 좀 더 해보겠습니다(지금은 이론적인 모습의 정규분포와 실제 실험 결과의 모습이 비슷한지 여부만 파악하면 되겠습니다).
10번만 실험을 하였을 때도 600번의 결과 중 1이 나온 횟수가 80 ~ 120 사이에, 즉 100에 가깝게 존재하는 것을 확인할 수 있지만 여전히 정규분포와의 모습이 다릅니다.

"주사위 600번 던졌을 때 1이 나오는 횟수 세기" 10번 실험
아래 그림은 위와 같은 실험을 총 100번 한 결과입니다. 10번 실험의 결과보다 정규분포의 모습과 가까워졌지만 여전히 오차가 많이 나는 것을 볼 수 있습니다.

"주사위 600번 던졌을 때 1이 나오는 횟수 세기" 100번 실험
아래 그림은 위와 같은 실험을 총 1,000번 한 결과입니다. 100번한 결과에 비해 정규분포와 오차가 많이 줄어든 것을 확인할 수 있습니다.

"주사위 600번 던졌을 때 1이 나오는 횟수 세기" 1,000번 실험
아래 그림은 위와 같은 실험을 총 10,000번 한 결과입니다. 위의 결과들에 비해 실험 결과와 정규분포가 거의 일치하는 것을 볼 수 있습니다.

"주사위 600번 던졌을 때 1이 나오는 횟수 세기" 10,000번 실험
여기서 우리가 알 수 있는 사실은 실험 횟수가 많을수록, 즉 표본이 많을 수록 우리가 관찰한 결과는 정규분포를 따른다는 것을 알 수 있습니다.
그래서 많은 연속된 값을 가지는 측정 값은 정규분포를 따른다는 가정이 대부분이고, 실제로 키, 몸무게, 성적 및 자연 현상에서 나타나는 대부분 관측 결과들이 정규분포를 따릅니다(물론 전부는 아닙니다).
그렇다면 위 그래프 중 빨간색의 정규분포 그래프는 어떻게 구한 것일까요? 바로 이항분포에서 근사 된 것입니다.
이항분포는 발생할 확률이 \(p\)인 사건을 \(n\)번 시행하여 사건 발생 횟수에 따른 확률을 나타낸 것이고 이를 \(B(n, p)\)로 표현합니다.
세상의 사건은 독립 사건이라고 볼 수 있는 경우가 많으며, 대부분이 이항분포를 따른다고 볼 수 있습니다.
예를 들어 동전을 100번 던져서 앞면이 나올 확률은 \(B(100, 0.5)\)이며, 아까 우리가 실험했던 600번 던졌을 때 1이 나올 확률은 \(B(600, \frac{1}{6})\)이라고 표현할 수 있습니다.
즉 이항분포를 따르는 독립 사건이 많으며 정규분포가 이항분포를 근사할 수 있으면, 정규분포는 세상의 많은 사건들을 설명할 수 있게 됩니다.
그리고 실제로 \(n\), 즉 시행 횟수가 커질수록 이항분포는 정규분포와 유사해진다고 합니다.
따라서 \(n\)이 커진다면 이항분포 \(B(n, p)\)는 정규분포 \(N(np, np(1-p))\)와 매우 유사해집니다.
그리고 보통 \(n\)이 30 이상일 때, 정규분포와 유사한 모습을 가진다고 합니다.
즉 위의 그림에서 빨간색 정규분포는 아래의 이항분포를 \(n\)이 무수히 많다고 가정하였을 때의 정규분포를 나타낸 것입니다.
따라서 위의 빨간 정규분포는 평균이 100이고 분산(표준편차의 제곱, \(\sigma^2\))이 83.3을 따르는 정규분포인 것입니다. 따라서 아래와 같이 우리는 표현할 수 있습니다.
결론적으로 실제로 우리가 주사위를 던지는 행위는 이산적인 분포인 이항분포를 따르지만, 그 횟수가 증가하면 이항분포는 정규분포와 근사하게 됩니다. 따라서 우리의 실험횟수가 10에서 10,000까지 증가하였을 때, 아래 그림처럼 이항분포의 모습이 정규분포와 거의 동일해지는 것을 확인할 수 있었던 것이죠.

"주사위 600번 던졌을 때 1이 나오는 횟수 세기" 10,000번 실험
그리고 우리가 위의 실험에서 1이 나타나는 횟수(x축)를 확률 변수 \(X\)라고 하였을 때, "X가 정규분포 \(N(100, 83.3)\)을 따른다"라는 표기는 아래와 같이 합니다.
그럼 표준정규분포란 무엇일까요? 정규분포는 평균과 표준편차에 의해 그 모습이 다양하게 나타날 수 있습니다. 아래 그림은 같은 실험을 했지만 각 세 번의 실험의 평균과 표준편차의 결과가 다르게 나온 모습입니다.

같은 실험, 다른 평균과 표준편차의 결과
표준졍규분포는 평균이 0, 표준편차와 분산이 1인 정규분포를 의미합니다.
따라서 표준정규분포는 위와 같은 다양한 평균과 표준편차를 가진 결과를 표준화하여 평균이 0이고, 분산과 표준편차가 1인 새로운 분포로 그리는 결과입니다.
이렇게 정규분포를 표준정규분포로 바꾸는 과정을 표준화라고 합니다.
표준정규분포의 정의와 그 분포의 모습은 아래와 같습니다.

표준정규분포
그럼 표준화는 어떻게 하며, 왜 하는 것일까요? 서로 다른 세 정규분포에서 우리는 1이 나온 횟수가 115회 이상일 확률을 구하고 싶다고 가정을 해봅시다.
정규분포는 확률을 의미하기 때문에 그래프의 면적을 적분으로 구하면 1이 된다는 사실은 알고계실겁니다.
만약 우리가 1이 나온 횟수가 115회 이상일 확률을 구하려면, 각각의 분포에서 115회 이후의 그래프 면적을 구해야 합니다.
하지만 그래프에서 보시다시피, 세 그래프의 모양은 각각 다르기 때문에 실험마다 우리가 구하고자하는 값을 매번 계산해야하는 번거로움이 존재합니다.
따라서 우리는 매번 다르게 나오는 실험의 분포마다 계산하기가 번거롭기 때문에, 모든 계산을 표준정규분포에서 하기위해서 각 분포를 모두 표준화 하기로 합니다.
이렇게 표준화된 확률 변수를 \(Z\)라고 합니다. 즉 우리는 우리의 확률 변수인 \(X\)를 표준화된 확률 변수인 \(Z\)로 표준화 하는 것이지요.
그리고 그 표준화 하는 방법은 아래처럼 각 확률 변수에 평균을 빼준 값을 표준편차로 나누는 것입니다.
그럼 아래 그림으로 정규분포의 표준화와 표준화 된 표준정규분포에서 원하는 확률을 구하는 방법에 대해 예시를 보여드리도록 하겠습니다.
먼저 위에서부터 계속 그려왔던 평균이 100, 분산(표준편차의 제곱)이 83.3인 정규분포를 표준화 하겠습니다.
그럼 모든 확률 변수 \(X\)에 대해 100을 빼주고 \(\sqrt{83.3}\)으로 나누어야 합니다.
그럼 아래 그림과같이 평균이 100, 분산이 83.3인 정규분포가 평균이 0, 분산(표준편차)가 1인 표준정규분포로 표준화 됩니다.
그럼 기존 정규분포에서 구하고 싶었던 1이 나온 횟수가 115회 이상인 확률을 표준정규분포에서는 어떻게 구할까요? 115에 대해 평균 100과 분산 83.3으로 표준화 하면 아래와 같습니다.

정규분포의 표준화
즉 우리는 1이 나온 횟수가 115 이상일 확률을 표준정규분포에서 1.64 이상인 영역을 구하면 되는 것입니다.
그리고 \(Z\)에 대한 표준정규분포의 면적은 표준정규분포표라는 것에 세세하게 나와있기 때문에 우리는 그 표를 참고하여 더 쉽게 확률 계산을 할 수 있는 것입니다.
따라서 표준화 된 표준정규분포표를 보고 손쉽게 확률 계산을 할 수 있기 때문에 우리는 정규분포를 표준화 하려고 하는 것입니다.
t-distribution (Student's t-distribution) ”
앞서 정규분포와 표준정규분포에 대해 간단히 알아보았습니다. 이제 t-SNE에 대해 알아보기 전에 t 분포에 대해 집고 넘어가도록 하겠습니다.
t 분포(t-distribution)는 스튜던트 t 분포(Student's t-distribution)와 동일한 용어입니다.
여담으로 스튜던트는 통계학의 개척자라고 불리는 영국의 윌리엄 실리 고셋(William Sealy Gosset)의 가명입니다.
유명 맥주 양조장인 기네스에 양조 기술자로 일을 하던 중, 보리의 질을 평가하기 위해 획기적인 방법인 t 분포에 대한 논문을 발표하였습니다.
하지만 당시 회사는 기술 유출을 우려하여 직원 이름으로 논문을 발표하지 못하게 하는 규정이 있었고, 어쩔 수 없이 가명인 student를 사용하여 논문을 발표하였습니다.
이것이 바로 Student's t-distribution, 즉 t 분포가 나오게 된 이야기입니다.

윌리엄 실리 고셋(William Sealy Gosset), 출처: 위키피디아
그럼 t 분포는 무엇일까요? 먼저 위에서 계속 봐왔던 정규분포를 다시 한 번 보도록 합시다.
위에서 이야기 했듯이 주사위를 600번 던져서 1이 나온 횟수는 평균적으로 100에 가까워야할 것입니다.
하지만 공교롭게도 우리가 시간이 없어서 주사위 600번 던지는 실험을 5번밖에 못했다고 가정합시다(총 3,000번 던지는 격).
수학적으로 생각했을 때 600번 던지는 각각의 5번 실험 중, 1이 나오는 횟수는 100에 가까워야하지만 실험은 늘 그렇듯 우리 맘대로 되지 않죠.
그래서 각 5번의 실험 중 1이 나온 횟수가 600번 중에 아래 그림과처럼 100번에 많이 떨어지게 나왔다고 가정 해봅시다.
그럼 우리는 아래 실험을 가지고 수학적으로, 즉 이론적으로 예측 되어야할 빨간색의 정규분포를 예측할 수 있을까요? 불가능합니다.

실제 기대하는 정규분포와 편향된 결과
즉 우리가 실제로 하는 실험은 수학적 이론과 결과가 많이 다른 경우가 많습니다.
이러한 문제의 해결방법은 표본을 많이 뽑거나 실험을 무수히 많이 하는 방법이 있습니다만, 시간과 자원은 한정적이기 때문에 실생활에서 불가능한 경우가 많죠.
즉 정규분포는 적은 표본에 대해서 신뢰도가 낮아지는 문제점이 발생합니다.
따라서 t 분포는 이렇게 적은 표본이 편향되는 문제점을 완화하기 위해 등장한 분포입니다.
아래 그림은 검은색의 표준정규분포와 자유도(degree of freedom)에 따른 t 분포를 보여줍니다.
여기서 자유도의 개념은 뒤에서 아주 간단하게 알아보도록 하고, 지금은 자유도가 표본의 개수라고 생각하시면 될 것 같습니다.
아래 그림에서 보듯이 t 분포 또한 평균이 0인 그래프이며, 정규분포와 동일하게 좌우 대칭이고 종 모양인 것을 알 수 있습니다.
그리고 가장 중요한 사실이 바로 꼬리쪽의 두께가 자유도에 따라 달라진다는 것입니다.
검은색의 정규분포의 꼬리가 가장 얇고, 자유도가 가장 작은(표본이 가장 적은) t 분포의 꼬리가 넓습니다. 그리고 자유도가 높아질수록 꼬리가 얇아지는 것을 확인할 수 있죠.
이러한 이유는 바로 표본이 적을 때, 즉 자유도가 작을 때 신뢰도가 낮아지는 문제를 해결하기 위해 예측 범위를 꼬리쪽으로 갈수록 높이려는 것입니다.

표준정규분포와 t 분포
그럼 우리가 예측할 수 있는 것이 있습니다.
자유도가 커질수록(표본이 커질수록) 꼬리 부분의 확률이 작아지면서 폭이 좁아질 것이고 표준정규분포와 그 모양이 비슷해질 것입니다.
실제로 아래 그림에서 보면 자유도가 30인 t 분포와 표준정규분포의 모습이 거의 흡사한 것을 볼 수 있습니다.
실제로 표본의 크기가 30 이상이면 t 분포는 표준정규분포와 거의 유사하다고 판단하며, 그때부터는 정규분포를 사용합니다. 그리고 표본의 크기가 120 이상이 되면 표준정규분포와 거의 동일해집니다.
그리고 위에서 말한 자유도는 표본의 개수, 즉 표본의 크기로 생각하라 하였지만 더 정확하게는 (표본크기-1)로 표현합니다.

표준정규분포와 자유도가 30인 t 분포
즉 우리는 t 분포를 표본의 크기가 30 이하인 것에 대해 표준정규분포를 사용하기에는 신뢰도가 떨어지므로 예측 범위를 꼬리쪽에 대해 넓히기 위해 사용하며, 표본의 크기가 30 이상인 경우에는 정규분포와 t 분포가 거의 흡사하여 표준정규분포를 사용한다고 정리할 수 있습니다.
그리고 t 분포는 정규분포와 다르게 확률을 구하기 위해 사용하는 것이 아니라 신뢰구간, 신뢰도, 가설 검정을 위해 사용됩니다.
사실 t 분포의 식을 이해하고, 자유도에 대한 개념을 정확히 이해하기 위해서는 모평균, 모표준편차, 표본평균, 표본표준편차 등의 개념을 숙지하고 있어야 합니다.
"표본분산의 기댓값이 모분산이며, 표본평균의 기댓값은 모평균이다, 모분산의 추정량인 표본분산을 구하기 위해 표본의 크기 \(n\)이 아닌 \(n-1\)로 나누는 것은 자유도와 관계 있다" 등 수학적 개념을 알아야 합니다.
사실 이러한 모평균과 모분산, 표본평균과 표본분산의 관계에 대한 수학적 유도를 천천히 살펴보면 그리 어렵지 않습니다만, 더 깊은 내용은 다루지 않겠습니다.
다만 여기서 t 분포에 대해 알아야할 부분은 아래와 같습니다.
- 30보다 작은 적은 표본에 대해서는 정규분포보다 t 분포를 이용하여 예측하는 것이 더 정확하다.
- 30이상의 표본의 t 분포는 정규분포와 비슷해지며, 이때부터는 정규분포를 사용한다.
- t 분포의 자유도는 표본 크기와 관련 있으며, 자유도(표본 크기)가 작아지면 꼬리 부분의 예측 범위를 넓히기 위해 t 분포의 꼬리 부분이 두꺼워진다.
- t 분포는 정규분포와 다르게 확률 계산을 위해 사용되는 것이 아니라 신뢰구간, 신뢰도, 가설 검정을 위해 사용된다.
- 적은 표본으로 모평균을 추정하고 모집단이 정규분포를 따르는 것을 예측할 수 있지만, 모표준편차를 모를 때 t 분포를 사용한다.
”
그럼 이제 t-SNE에 대해 이야기 해보겠습니다.
먼저 t-SNE는 데이터의 manifold를 잘 학습하여 데이터의 차원을 축소하거나 의미있는 특징 추출 혹은 데이터를 가시화하기 위한 manifold learning의 일종입니다(Manifold와 manifold Learning에 대한 설명은 이전글을 참고하시기 바랍니다).
먼저 아주 간단히 t-SNE의 원리에 대해 설명을 해보겠습니다. t-SNE의 기본적인 원리는 고차원의 데이터간 거리를 저차원으로 축소하였을 때도 똑같이 유지하는 것입니다.
물론 여기서 말하는 거리는 유클리드 거리(Euclidean distance)가 아니라 확률로써 나타내긴 합니다만, t-SNE가 사용한 기본 개념은 앞서 말한 것처럼 단순합니다.
먼저 아래 그림에서 고차원의 원래의 데이터를 \(x_1,\,x_2,\,x_3,\,x_4,\,x_5,\,x_6\)이라고 하고, 각각의 저차원에 대응된 데이터를 \(y_1,\,y_2,\,y_3,\,y_4,\,y_5,\,y_6\)라고 가정 합시다.
아래 그림에서 \(x_1\)을 기준점이라고 가정했을 때, 고차원에서든 저차원에서든 \(x_1\)과 그 나머지 데이터들(\(x_2,\,x_3,\,x_4,\,x_5,\,x_6\))간의 거리(유사도)를 우리는 모종의 방법으로 측정할 수 있을 것입니다.
그리고 모종의 방법으로 구한 실제 데이터들이 분포하고 있는 고차원에서의 데이터들간의 거리(유사도)를 저차원으로 압축했을 때도 비슷하게 유지하게끔 학습을 하는 것입니다.
즉 맨 처음에 저차원에서 랜덤으로 분포된 \(y_1,\,y_2,\,y_3,\,y_4,\,y_5,\,y_6\)에 대해서도 저차원에서의 기준점 \(y_1\)(\(x_1\)에 대응되는 점)에 대해 나머지 데이터와의 거리를 고차원에서의 결과와 유사하게끔 학습을 하는 것이지요.
그럼 차츰차츰 학습이 진행될수록 처음에 저차원에 무작위로 분포된 \(y_1,\,y_2,\,y_3,\,y_4,\,y_5,\,y_6\)들이 실제 고차원에서와의 거리와 유사하게끔 배치가 될 것이고 우리는 그 결과(데이터의 분포)를 가시화하여 볼 수 있는 것 입니다.

t-SNE의 기본 원리
고차원에서의 데이터간의 거리(유사도)
그렇다면 구체적으로 어떻게 데이터간의 거리(유사도)를 구할까요? 결론부터 말하자면 고차원의 원래의 데이터는 정규분포를, 저차원으로 임베딩 된 데이터는 t 분포를 이용하여 데이터간의 거리(유사도)를 구합니다.
먼저 고차원의 총 \(n\)개의 데이터에 대해 특정 두개의 데이터 \(x_i\)와 \(x_j\)의 정규분포에 관한 거리(유사도) \(p_{ij}\)는 아래와 같이 정의됩니다.
그렇다면 \(p_{i|j}\)와 \(p_{j|i}\)의 정의는 무엇이길래 두 데이터 \(x_i\)와 \(x_j\)의 유사도가 저렇게 표현 될까요?
먼저 \(x_i\)를 기준으로 바라본 \(x_j\)의 유사도 \(p_{j|i}\)는 아래와 같이 정의됩니다.
그럼 이제 우리는 \(x_j\)를 기준으로 바라본 \(x_i\)의 유사도 \(p_{i|j}\)의 정의도 유추할 수 있게 됩니다.
그럼 우리는 여기서 의문이 듭니다. \(x_i\)를 기준으로 \(x_j\)를 바라보나, \(x_j\)의 기준으로 \(x_i\)를 바라보나 두 점간의 유사도는 항상 같아야할 것 같은데 \(p_{j|i}\)와 \(p_{i|j}\)는 수식적으로 다른 값을 가지게 됩니다.
그 이유는 아래 그림으로 설명 가능합니다.
아래 \(x_1\)과 \(x_2\)를 기준으로 \(x_4\)는 비슷한 거리에 위치합니다.
하지만 \(x_1\)을 기준으로 가장 가까운 점은 \(x_2\)이고 가장 먼 점은 \(x_3\)입니다.
그리고 \(x_2\)를 기준으로 가장 가까운 점은 \(x_3\)이고 가장 먼 점은 \(x_3\)가 아닙니다. 즉 기준을 어디로 삼느냐에 따라 다른 데이터 간의 거리의 분포가 달라지기 때문에 결국 \(p_{j|i}\)와 \(p_{i|j}\)가 달라지는 것입니다.

두 데이터간의 기준에 따른 유사도가 다르게 나타나는 이유
따라서 우리는 두 점 혹은 두 데이터 \(x_1\)과 \(x_2\) 사이의 거리(유사도)가 어느 기준을 잡아도 똑같아지기를 원하기 때문에 각 두 확률 \(p_{j|i}\)와 \(p_{i|j}\)의 평균값을 최종적인 두 점의 유사도로 정의합니다.
저차원에서의 데이터간의 거리(유사도)
위에서 잠깐 저차원의 데이터간 거리는 t 분포를 이용하여 구한다고 하였습니다.
저차원에서 t 분포를 사용하는 이유는 뒤에서 알아보기로 하고, 먼저 저차원에 임베딩 된 데이터에 대해 특정 두개의 데이터 \(y_i\)와 \(y_j\)의 t 분포에 관한 거리(유사도) \(q_{ij}\)는 아래와 같이 정의됩니다.
위의 식이 바로 t 분포를 의미하며, \(q_{ij}\)는 \(y_i\)와 \(y_j\) 중 어떤 기준을 잡더라도 같기 때문에 위의 정의 그대로 사용합니다. 두 점 \(y_i\)와 \(y_j\) 중 어떤 기준을 잡더라도 \(q_{ij}\)가 같은 이유는 정의의 분모에서 \(k\)와 \(l\)이 서로 다른 데이터의 쌍에 대해 계산한 값을 모두 더하기 때문입니다. 그리고 기준에 따라 달라지는 분산에 해당하는 \(\sigma^2\) 부분이 사라졌기 때문이죠.
고차원에서 정규분포를 사용하는 이유
그럼 여기서 의문이 한 가지 들 수 있습니다.
저차원에 대해서는 t 분포를 이용해서 한 번만 계산하여 \(q_{ij}\)를 구할 수 있는데, 왜 고차원에 대해서는 번거롭게 \(p_{j|i}\)와 \(p_{i|j}\)를 각각 계산하여 최종적으로 \(p_{ij}\)를 구할까요?
바로 정규분포를 이용하여 들어가게 되는 \(\sigma_i\)와 \(\sigma_j\)가 중요한 역할을 하게 되기 때문입니다.
먼저 \(p_{ij}\)를 구하는 정의가 위에서 언급한 \(q_{ij}\)와 비슷하게 아래의 정의라고 가정해보겠습니다. 추가로 \(x_1\)이 다른 점들에 비해 엄청 멀리 떨어져있는 outlier (이상치)라고 가정해보겠습니다.
위에서 언급하였듯이, \(x_1\)은 다른 점들에 비해 멀리 떨어져있기 때문에 \(|x_i-x_j|^2\)은 커지게 되고 전체적인 \(p_{ij}\)값은 작아지게 됩니다. 이렇게 \(p_{ij}\)값이 작아지면 자연스레 \(q_{ij}\)가 받는 영향도 작아지고 학습이 잘 일어나지 않게 되는 것이지요. 즉 위 방법을 사용할 경우, 이상치에 대해 치명적이기 때문에 \(p_{ij}\)를 구하기 위해서 \(p_{j|i}\)와 \(p_{i|j}\)를 각각 구해 각 데이터들에 대한 정보를 모두 잘 수용할 수 있도록 하는 것 입니다. 그리고 이것이 t-SNE 알고리즘을 robust하게 만들게 되고, 지금까지 많은 사람들이 사용하는 이유이기도 합니다.
저차원에서 t 분포를 사용하는 이유
위에서 고차원 데이터 사이의 거리(유사도)를 구하기 위해서 정규분포를 사용한 이유에 대해 알아보았습니다.
그럼 저차원에서도 고차원에서의 정의와 비슷하게 사용하면 되는데 굳이 t 분포를 사용한 것에 대한 의문이 생길 것입니다.
- 아래와 같이 \(q_{ij}\)도 \(p_{ij}\)와 비슷하게 정의 된다고 가정해보겠습니다.
\[Assumption:\,q_{ij}\,=\,\frac{(|y_i-y_j|^2)^{-1}}{\sum_{k\ne l}(|y_k-y_l|^2)^{-1}}\]
위와 같이 \(q_{ij}\)를 정의 한다면, \(y_i\)와 \(y_j\)가 거의 유사해서 \((|y_i-y_j|^2)^{-1}\)은 무한대(\(\infty\))에 가까워질 것입니다. 따라서 이러한 문제점을 해결하기 위해서 1을 더하여 최소한 1 이상인 값이 나오도록 만드는 것입니다. 이것이 바로 t 분포이며, 기존 SNE 알고리즘을 개선하여 t-SNE가 더 안정적으로 작동하게 되는 이유 중 하나입니다. - 그리고 윗 부분에서 t 분포에 대해 설명을 진행할 때, t 분포는 기본적으로 낮은 확률에 대해 선택의 폭을 넓히기 위해 분포의 꼬리 부분이 정규분포(가우스 분포)보다 두껍다고 언급하였습니다.
만약 저차원으로 임베딩 된 두 점 \(y_i\)와 \(y_j\)가 초기에 너무 가깝게 배치가 되었다고 가정하였을 때, t 분포의 이러한 특성은 학습 중 gradient를 크게 가져올 수 있기 때문에 빠르게 학습이 된다는 장점도 있습니다.
즉 너무 가깝게 초기화 된 noise 데이터들의 영향을 덜 받게 되는 것이지요.
- 마지막으로 저차원에서 t 분포를 사용하는 이유는 고차원에서 가까웠던 두 데이터를 저차원에서는 상대적으로 더 가깝게끔, 고차원에서 멀었던 두 데이터는 저차원에서 상대적으로 더 멀게끔 학습이 가능하기 때문입니다.
아래 그림과 같이 고차원에서의 기준점과 저차원으로 임베딩 된 기준점을 각각 \(x_1\), \(y_1\)으로 가정을 했을 때 가까운 점과 멀리 떨어진 점을 비교해봅시다.
그림에서 빨간 분포가 꼬리쪽인 두꺼운 t 분포이고 검은색은 표준정규분포입니다. 그리고 우리는 각 데이터간의 거리(유사도)룰 확률로써 판단합니다. 즉 우리는 데이터간의 거리를 세로축인 확률로 비교하고, 그 확률이 같은 지점에 해당되는 가로축이 바로 데이터가 분포한 위치가 됩니다. 실제로 가까운 지점인 \(x_2\)와 \(y_2\)는 각각 고차원, 저차원에 분포된 데이터이므로 정규분포와 t 분포에 매칭이 됩니다. 아래 그림에서 거리가 같은, 즉 확률이 같은 \(x_2\)와 \(y_2\)가 위치한 가로축의 지점이 각각 고차원, 저차원에서 \(x_1\)와 \(y_1\)에 비해 떨어진 지점이 되는 것입니다. 그 결과 저차원에서의 거리(\(y_1\)과 \(y_2\) 사이의 거리)가 고차원에서의 거리(\(x_1\)과 \(x_2\) 사이의 거리)거리 보다 가까운 것을 알 수 있습니다. 반대로 멀리 떨어진 데이터인 \(x_3\)과 \(x_3\)는 저차원 사이의 거리가 고차원 사이의 거리보다 먼 것을 확인할 수 있죠. 결과로 볼 수 있듯이 저차원에서 t 분포를 사용할 경우 가까운 지점은 더 가깝게, 멀리있는 지점은 더 멀게 배치가 되는 것을 확인할 수 있습니다. 이는 데이터의 특징을 더 분명하게 해주기 때문에 저차원(2, 3차원)밖에 볼 수 없는 사람이 결과를 보기에 더 효과적으로 보이게끔 해주는 것이지요.

저차원 임베딩에서 t 분포를 사용하는 이유
실제로 아래 그림은 0 ~ 9까지의 손글씨 데이터인 MNIST를 가시화 한 결과입니다.
t-SNE를 사용했을 때, 숫자별로 그 특징이 잘 묶이고 구분이 잘 되는 것을 확인할 수 있습니다.

t-SNE를 이용한 MNIST 데이터의 2차원 가시화
t-SNE의 장점
t-SNE는 특징을 추출하거나, 데이터의 특징을 가시화하기에 아주 robust한 알고리즘입니다.
- 기존 PCA (주성분 분석)과 같은 선형 변환은 데이터를 저차원으로 임베딩하여 가시화할 때 겹쳐서 뭉게지는 부분이 많이 생겼지만 unsupervised learning의 일종인 t-SNE를 사용한다면 그런 문제점이 많이 해소됩니다.
- 또한 저차원 임베딩을 t 분포 기반으로하기 때문에 기존 SNE 방법과 같이 저차원 임베딩에서 정규분포(가우스 분포)를 사용했을 때 나타나는 crowding 문제점이 해결됩니다(특정 거리 이상부터는 학습에 반영이 되지 않는 문제점).
- 또한 다른 차원 축소 알고리즘에 비해 hyperparameter의 영향이 적고 이상치(outlier)에 둔감하다는 장점이 있습니다.
t-SNE의 단점
t-SNE는 특징을 추출하거나, 데이터의 특징을 가시화하기에 아주 robust한 알고리즘이지만 문제점 역시 존재합니다.
- 먼저 시간이 오래 걸립니다. 특정 기준 데이터를 정하고 나머지 데이터에 대해 확률로써 거리(유사도)를 계산합니다.
이 과정을 모든 데이터를 돌면서 한 번씩 기준을 삼으며 돌기때문에 time complexity (시간 복잡도)가 \(O(n^2)\)입니다(알고리즘의 시간 복잡도를 이야기할 때 big O notation을 사용합니다).
따라서 데이터 수가 많고 그 데이터를 모두 가시화 하려 한다면 몇 시간 이상 걸리는 경우도 많습니다. 아래에서 설명할 UMAP을 사용한다면 이러한 문제점을 해결할 수 있습니다.
-
또한 너무 높은 차원을 가진 데이터를 바로 2, 3차원으로 축소하는 것이 불가능합니다. 성능이 떨어지는 것은 물론이고 시간이 너무 오래 걸리게 됩니다.
따라서 보통 128차원의 raw 데이터를 autoencoder를 통해 32차원으로 줄어든 잠재 변수(latent variable)를 구한 후, 32차원을 2, 3차원으로 줄이기 위해 t-SNE를 사용합니다.
즉 raw 데이터의 차원을 한 단계 축소 한 후, 한 단계 축소 된 데이터를 다시 한 번 축소하여 가시화 합니다. 보통 50차원 이내로 raw 데이터를 압축 후 t-SNE를 사용합니다.
- 저차원으로 임베딩되어 가시화 된 결과에서 각 데이터간의 거리는 실제 데이터 간의 거리를 의미하지 않습니다. 또한 데이터들의 군집의 크기 역시 의미가 없습니다.
- 저차원으로 임베딩 되는 과정에 어쩔 수 없이 정보 손실이 발생하며 데이터 왜곡이 일어납니다.
-
t-SNE를 이용할 때 저차원 데이터들은 처음에 랜덤으로 분포하게 됩니다. 이렇게 랜덤으로 분포된 데이터들이 학습을 진행하며서 가까운 것끼리 묶이고 다른 것끼리 멀어지는 것이지요.
하지만 맨 처음 랜덤으로 저차원에 데이터가 분포되기 때문에 매번 돌릴 때 마다 결과가 다르게 나옵니다. 맨 처음에 딥러닝 모델의 가중치들을 초기화할 때 랜덤으로 하게 한다면 학습된 모델의 결과가 조금씩 다른 것과 같은 원리입니다.
하지만 결과가 다르다고 해서 어쩔 땐 결과가 잘 나오고 어쩔 땐 안나오고 이런 것은 아니라, 아래 그림과 같이 약간의 분포의 위치만 달라지는 정도입니다.
이 문제를 해결하기 위해서는 매번 할 때마다 같은 random seed로 고정하고 t-SNE를 돌리면 됩니다.
이러한 이유 때문에 어떤 특정 데이터들을 t-SNE의 결과로 representation 하기에 한계가 존재합니다(따라서 데이터를 representation 하기 위해서는 autoencoder의 결과인 잠재 변수를 많이 사용합니다).
그래서 대부분 t-SNE는 데이터의 특징 분포를 가시화 하는 용도로 사용됩니다.
- 마지막으로 큰 데이터셋에 대해 t-SNE를 사용하게 되면, 특징의 구분이 여럽고 명확해지지 않는다는 단점이 있습니다. 아래에서 설명할 UMAP을 사용한다면 이러한 문제점이 해결 될 수 있습니다.
매번 다르게 나오는 t-SNE의 분포 결과 예시
t-SNE는 위와 같은 정의와 원리로 작동하며, 데이터의 특징을 가시화 하는 데 아주 강건한 알고리즘 입니다.
그리고 t 분포를 기반으로 저차원으로 임베딩 된 데이터간의 거리(유사도)를 구하고, 데이터의 거리(유사도)는 확률로써 나타내기 때문에 t-distributed Stochastic Neighbor Embedding (t-SNE)이라는 이름이 붙여진 것입니다.
그리고 아래에 t-SNE의 논문 링크를 달아놓겠습니다.
UMAP
UMAP은 Uniform Manifold Approximation and Projection의 약자입니다. UMAP은 성능이 좋고 t-SNE의 많은 문제점을 해결한 것에 의의가 있습니다(나중에 UMAP과 t-SNE의 성능 차이는 별반 다를 것이 없고 둘을 적용하기 전 데이터 전처리, 초기화 방법이 더 중요하다는 논문이 등장). UMAP의 컨셉도 서로 먼 데이터는 더 멀리, 가까운 데이터는 더 가깝게 하려고하는 t-SNE와 매우 유사합니다. 하지만 UMAP이 사용하는 방법은 t-SNE와 전혀 다른 수학적 원리를 기반으로 합니다. 이러한 수학적 기반을 이용하여 t-SNE보다 더 global한 데이터 분포를 학습할 수 있게 됩니다.
”
먼저 UMAP의 원리를 설명하기 앞서 UMAP의 결과와 t-SNE의 결과부터 보고, t-SNE와 UMAP의 차이점을 알아보도록 하겠습니다. 아래는 UMAP과 t-SNE를 통해 여러 옷가지의 이미지를 종류별로 가시화한 결과입니다. t-SNE와 UMAP 모두 신발은 신발끼리 옷은 옷끼리 등 잘 묶이는 것을 확인할 수 있지만, UMAP으로 데이터 특징을 가시화 한 결과가 군집이 더 확실하게 되어있는 것을 볼 수 있습니다.

UMAP과 t-SNE를 사용한 옷가지 이미지 특징 가시화 결과, 출처:https://pair-code.github.io/understanding-umap/
UMAP의 장점 및 t-SNE에 비해 개선된 점
그럼 t-SNE의 어떤 부분이 UMAP에서 개선 되었는지, 그리고 UMAP의 장점이 무엇인지 간단히 알아보겠습니다.
- t-SNE에 비해 UMAP을 이용하여 결과를 가시화 하는 시간이 현저히 빨라졌습니다.
실제로 위의 이미지의 결과를 내기 위해서 UMAP은 4분이 걸렸지만 t-SNE는 27분이 걸렸다고 합니다.
- UMAP이 t-SNE의 결과에 비해 global한 구조를 잘 유지합니다. 이는 UMAP이 더 견고한 수학적 이론이 바탕으로 되었기 때문입니다(t-SNE에 사용된 확률분포의 이론이 더 하등하다는 뜻이 아니라, 데이터의 특징을 학습한다는 목적에 있어서 더 적절한 수학적 이론을 도입했다는 뜻).
UMAP의 원리
크게 봤을 때, UMAP과 t-SNE의 동작 방식은 유사합니다.
t-SNE는 고차원에서 각 두 점들에 대해 데이터가 비슷하면 높은 확률을, 데이터가 다르면 낮은 확률을 부여합니다.
그리고 저차원으로 임베딩 된 데이터에 대해서도 고차원의 확률 관계를 유사하게 맞추는 방식으로 학습 됩니다.
이는 우리가 두 데이터를 node로 볼 수 있고, 각 데이터 사이의 확률이 그 둘을 잇는 edge의 weight라고 생각할 수 있습니다.
즉 우리는 각 데이터가 분포되어 있고, 각 데이터를 잇는 edge의 weight는 확률인 weighted graph 형태로 생각할 수 있습니다.
UMAP 또한 이러한 고차원에서 각 데이터의 graph 관계를 저차원으로 임베딩 했을 때도 유사하게 잘 유지가 될 수 있도록 하는 학습이며, 전체적인 그림은 t-SNE와 유사하다고 할 수 있습니다.
그리고 UMAP이 더욱 적절한 수학적 이론을 기반으로 제작된 알고리즘이기에 고차원 데이터 간의 graph 구조(global 구조)가 저차원에서 t-SNE에 비해 더 잘 유지가 된다고 합니다.
그렇다면 UMAP은 그래프를 형성하는 과정이 어떻게 이루어질까요? 먼저 논문에서는 고차원의 데이터 구조를 잘 형성하기 위해 "fuzzy simplicial complex"를 구성한다고 합니다.
이는 "모호한 단순 복합체"로 해석할 수 있는데 왜 이러한 표현을 했는지는 아래 그림과 같이 설명하겠습니다.
아래 그림에서 윗 줄의 두 그림은 extent의 값이 다릅니다. 따라서 우리는 extent 값이 커질수록, 각 데이터의 주변의 범위 즉 반지름이 커지는 것을 확인할 수 있습니다.
아래 그림에서 아랫 줄의 두 그림은 n-nearest 값이 다릅니다. 따라서 우리는 n-nearest 값이 커질수록, 각 데이터가 연결된 다른 데이터의 수가 늘어나는 것을 확인할 수 있습니다.

UMAP이 데이터간 graph를 형성하는 방법, 출처:https://pair-code.github.io/understanding-umap/
UMAP에서는 데이터를 감싸고 있는 원이 만나는 두 데이터는 연결되기 때문에 각 데이터를 둘러싼 원의 크기는 매우 중요한 역할을 합니다.
왜냐하면 원이 너무 커지면 모든 데이터가 연결되고, 너무 작으면 고립된 데이터가 많이 생겨나기 때문이죠. 따라서 적절한 원의 크기를 정하는 것이 중요해집니다.
위에서 보았듯이, 데이터의 원의 크기는 extent와 각 데이터들의 n-nearest 데이터의 거리를 바탕으로 모종의 규칙을 적용하여 정해집니다.
따라서 각 데이터는 다른 반지름을 가진 원을 가지게 되고 이러한 원이 만나는 두 데이터는 연결 되는 것입니다.
하지만 여기서 만약 모든 데이터에 대해 원이 커지게 되면 모든 데이터가 연결되는 문제가 발생하기 때문에, fuzzy 개념을 이용하여 해결합니다.
즉 원의 반지름이 너무 커지게 되면 경계를 모호하게 하여 각 데이터간의 연결을 제한합니다.
그리고 이러한 규칙 때문에 특정 데이터가 하나도 연결이 안되는 경우가 발생하는 것을 방지하기 위해 가장 가까운 두 데이터는 무조건 연결하도록 합니다.
마지막으로 이러한 규칙으로 데이터를 연결한 후, 가까운 데이터들은 연결된 정도가 강하게(edge weight 크게), 먼 데이터는 연결된 정도가 약하게(edge weight 작게) 설정됩니다.
이는 위 그림에서 연결된 edge의 두께를 통해 확인할 수 있습니다.
그렇다면 위에서 논문에서 언급한 "fuzzy simplicial complex"가 "모호한 단순 복합체"로 해석될 수 있다 하였는데, 이는 결국 모호한 weighted graph라고 볼 수 있습니다.
그리고 이렇게 고차원에서 형성된 global 구조(graph 구조)를 저차원에서 동일하게 유지하려고 하는 것이 UMAP 입니다.
이는 t-SNE와 유사한 개념이지만, 최적화하는 데 트릭을 이용하여 t-SNE의 느린 시간을 개선하였습니다.
UMAP의 수학적 이론
위에서 UMAP의 기본 원리에 대해 전체적으로 살펴보았다면, 여기서는 조금 더 자세한 이야기를 해보겠습니다.
UMAP의 수학적 이론은 토폴로지 조합을 나타낼 수 있는 Čech complex를 기반으로 합니다(여기서 토폴로지(topology)란 위상수학을 의미하며, 수학 학문 중 꽤 최근에 등장한 학문입니다.
여기서 토폴로지라 함은 위상 즉 구조로 간단하게 생각하면 편할 것 같습니다). Čech complex에 도달하기 위해서는 simplex라는 개념을 사용합니다. 기하학적으로 k-simplex란 k+1개의 점으로 이루어진 블록이라는 뜻입니다.
예를 들어 0-simplex는 1개로 이루어진 점, 1-simplex는 2개의 점으로 이루어진 선, 2-simplex는 3개의 점으로 이루어진 삼각형 블록을 의미하는 것입니다. 아래 그림은 몇가지 simplex들의 예시입니다.
즉 우리는 여러 데이터를 이어 simplex를 만들 수 있으며, 여러개의 simplex를 결합하여 전체 데이터가 분포된 토폴로지(구조)를 알 수 있습니다.
그리고 이는 결국 Čech complex를 형성할 수 있게 되고, 이를 지표로 삼아 데이터 구조가 어떠한지 판단할 수 있게 됩니다.

k-simplex 예시, 출처: https://umap-learn.readthedocs.io/en/latest/how_umap_works.html
그렇다면 Čech complex는 과연 무엇을 의미할까요? Čech complex는 point cloud를 이용하여 토폴로지 정보, 즉 기하학 정보를 표현하는 simplicial complex (단순 복합체)입니다.
위에서 잠깐 "fuzzy simplicial complex"에 대해 이야기를 할 때 "단순 복합체라고 해석될 수 있다"라고 표현한 부분이 바로 Čech complex와 관련된 부분이지요.
Čech complex의 예시는 아래 그림을 통해 쉽게 이해할 수 있습니다.
아래에서 가장 왼쪽 그림처럼 데이터가 분포되어있다고 가정해봅시다. 그럼 이 분포의 토폴로지, 즉 기하학적 의미는 어떻게 표현할 수 있을까요?
그것은 이제 \(\varepsilon\)에 따라 데이터의 토폴로지는 달라집니다. 중간 그림은 \(\varepsilon\) 값이 5일 때, 가장 오른쪽 그림은 \(\varepsilon\) 값이 8일 때 point cloud를 표현한 그림입니다.
그리고 각 데이터의 원(cloud)이 만나는 데이터를 연결한 것이 바로 Čech complex이고, Čech complex는 그 모양이 \(\varepsilon\) 값에 따라 달리지는 것을 알 수 있죠.
마지막으로 이러한 Čech complex를 형성하는 것은 바로 위에서 언급한 k-simplex들인 것입니다.
그리고 각 데이터를 연결하여 여러 simplex를 만드는 edge의 두께는 원(cloud)이 많이 겹치면 두껍게, 덜 겹치면 얇게 표현 되어있습니다.
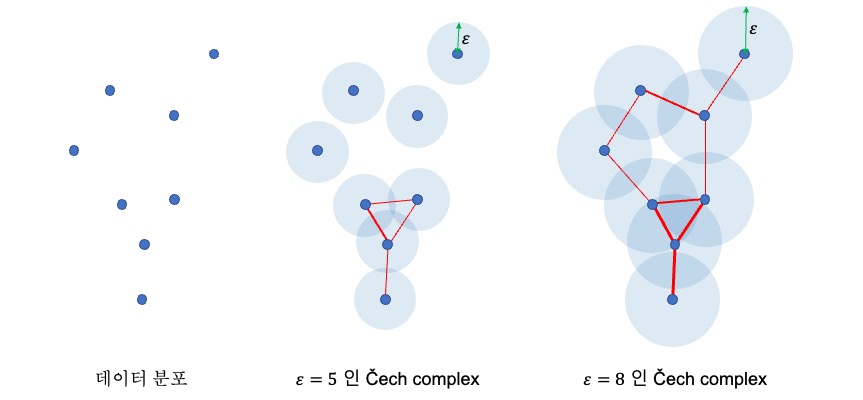
Čech complex 예시
그리고 UMAP의 원리 부분에서 언급하였듯이 Čech complex를 형성하기 위해 simplex를 만드는 과정에서 필요한 각 데이터를 둘러싸는 원(cloud)의 크기는 중요합니다.
왜냐하면 이 원의 크기에 따라 데이터가 분포한 토폴로지(global 구조)가 달라지기 때문이지요.
예를 들어 각 데이터를 둘러싼 원(cloud)의 크기가 너무 크면 모든 데이터가 연결되어 의미있는 구조가 나타나지 않고, 너무 작으면 연결이 하나도 되지 않는 점이 많이 생기게 됩니다.
따라서 적절한 데이터의 토폴로지를 만들기 위하여 UMAP에서는 extent와 각 데이터의 n-nearest 데이터 거리를 바탕으로 모종의 규칙을 통해 데이터 별로 다 다른 크기의 원(cloud)를 가지게끔 해주었습니다.
그래서 실제로 UMAP에서는 위의 Čech complex 예시 그림과 다르게 데이터를 감싸는 원(cloud)의 크기가 다른 것입니다.
하지만 이렇게 각 데이터 별로 다른 원(cloud)의 크기를 부여하였음에도 불구하고, 원의 크기가 커지면 모든 데이터가 연결되는 것은 불가피합니다.
따라서 원(cloud)의 반경에도 fuzzy 개념을 도입해서 자기를 감싸는 원 커져서 멀리 있는 데이터의 원(cloud)과 만나더라도 연결될 확률을 낮추는 개념을 도입하여, 데이터들이 무분별하게 연결되는 것을 막습니다.
그리고 fuzzy 때문에 하나도 연결이 안 된 데이터가 남아있지 않도록 방지하기 위해 가장 가까이 있는 데이터는 fuzzy와 상관없이 연결하게 하여, 모든 데이터가 하나 이상 연결 되게 강제하는 조건을 추가합니다.
아래 그림은 위에서 말한 데이터를 둘러싼 원(cloud)의 크기를 정하는 일련의 과정을 나타냅니다.
1번 그림에서 데이터는 uniform하게 분포가 되어있습니다. 이러한 경우라면 사실 데이터마다 원(cloud)의 크기를 다르게 할 이유가 없이, 적절한 원의 크기를 찾기만 한다면 전체적인 데이터의 manifold, 즉 토폴로지(global 구조)를 잘 찾을 수 있게 됩니다.
하지만 실제 세상에서는 2번 그림과 같이 데이터가 uniform하게 분배 되어있지 않습니다. 따라서 위에서 말한 방법으로 데이터 별로 데이터를 둘러싼 원(cloud)의 크기를 다르게 하는 것입니다.
그리고 3번은 각 데이터의 원(cloud)의 반격에서 멀어질수록 흐릿해지는 것을 볼 수 있는데, 이는 확률이 작아짐을 의미하는 fuzzy 이론을 적용시킨 그림입니다.
4번 그림은 이 모든 것을 고려하여 최종적인 데이터의 토포롤지를 형성할 수 있는 원(cloud)이 결정된 모습입니다.

데이터의 원(cloud)를 정하는 과정, 출처: https://umap-learn.readthedocs.io/en/latest/how_umap_works.html
따라서 논문에서는 고차원에서 데이터 구조(토폴로지)를 잘 파악하기 위해 Čech complex를 형성하고, 이를 "fuzzy simplicial complex"라고 부릅니다.
위와 같은 방법으로 고차원 데이터의 토폴로지(global 구조)를 형성한 후, 저차원으로 임베딩 된 데이터에서도 고차원의 토폴로지와 동일하게 유지가 되게끔 학습하는 방법이 바로 UMAP인 것입니다.
UMAP이 빠른 이유
위에서는 UMAP이 고차원 데이터에 대해 토폴로지(global 구조)를 형성하는 방법에 대해 알아보았습니다.
하지만 UMAP의 전체적인 컨셉은 t-SNE와 비슷하다고 하였지만 왜 t-SNE보다 빠른 것일까요?
- UMAP은 각 데이터에 대해 가까운 몇 개의 이웃 데이터에 대해서만 계산을 합니다. 왜냐하면 fuzzy 이론 때문에 데이터 중심에서 멀리 떨어질수록 다른 데이터와 결합확률은 0에 가까워진다고 합니다.
따라서 각 데이터에 대해 가까운 몇 개의 이웃 데이터에 대해서만 계산을 수행하여도 토폴로지(global 구조)를 잘 학습 한다고 합니다.
- 그리고 1번과 비슷한 맥락이지만 가까운 데이터에 대해서만 계산을 하고, 멀리 떨어진 데이터 몇 개만 추려서 멀리 떨어진 경우에 대해서 계산을 합니다. 즉 negative sampling을 수행하여 모든 데이터 연결 고리에 대해 하지 않는 것이지요.
즉 가까운 데이터 몇 개, 멀리 떨어진 데이터 몇 개 이런식으로 학습을 하는 것입니다. 여기서 사용된 negative sampling의 개념은 추후 word2vec을 구현할 때 학습 시간을 줄이기 위해 사용된 기법입니다.
이는 추후에 word2vec에 대한 글을 적을 때 한 번 더 등장할 것입니다.
(Negative sampling 예시: 예를 들어 모델이 queen이라는 단어에 대해 학습한다고 할 때, 모델은 queen과 유사한 단어와 유사하지 않은 단어들을 모두 학습하여 queen이란 단어의 의미를 파악할 것입니다. 이때 queen과 유사한 단어는 girl, woman과 같이 적은 반면에, queen과 관련이 없는 단어는 car, cookie, book, house, country, university 등 수많은 단어가 존재합니다. 우리는 유사한 단어에 대해서는 모두 학습을 하지만, 모델의 학습 시간을 줄이기 위해 수많은 유사하지 않은 모든 단어를 학습하지 않고 몇 개를 추려서 car, cookie, house 대해서만 학습을 하게 됩니다. 이렇게 유사하지 않은 수많은 단어 중 몇 개만 추려서 학습하는 것을 "negative sampling하여 학습한다"라고 표현합니다.) - 또한 UMAP은 저차원 데이터에 대해서 각 데이터의 연결 정도를 계산할 때 실제 사용되는 함수가 아닌 근사 함수를 사용하여 미분 속도를 높였습니다.
- 마지막으로 저차원 임베딩 데이터를 초기화할 때 랜덤으로 하지 않고 spectral embedding 기술을 이용하여 학습이 더 빨리 되게 만들었습니다.
UMAP의 단점
위에서 UMAP의 장점과 t-SNE에 비해 어떠한 점이 개선 되었는지 살펴보았습니다. 그리고 UMAP의 원리를 간단히 알아보았습니다.
UMAP이 많은 점을 개선하였지만, 단점도 여전히 존재합니다.
- Hyperparameter의 영향이 상대적으로 크게 작용합니다. 하지만 시간이 빠르다는 장점은 여러번 실험할 수 있다는 것을 방증하기 때문에 큰 문제점은 되지 않습니다.
- t-SNE에도 해당되는 문제점이며, 저차원으로 임베딩되어 가시화 된 결과에서 각 데이터간의 거리는 실제 데이터 간의 거리를 의미하지 않습니다. 또한 데이터들의 군집의 크기 역시 의미가 없습니다.
- t-SNE에도 해당되는 문제점이며, 저차원으로 임베딩 되는 과정에 어쩔 수 없이 정보 손실이 발생하며 데이터 왜곡이 일어납니다.
마지막으로 아래에 UMAP 논문 링크를 걸어놓겠습니다.
추가로 t-SNE와 UMAP의 결과를 즉석으로 비교해볼 수 있고, 설명 잘 되어있는 글 링크를 걸어놓겠습니다.
이렇게 해서 manifold learning의 일종인 t-SNE와 UMAP 알고리즘에 대해 알아보았습니다.
다음에는 MNIST 숫자 손글씨 데이터를 바탕으로 vanilla autoencoder, convolutional autoencoder를 구현해보고 각각에 대해서 노이즈를 추가하는 denoising autoencoder도 구현해보겠습니다.
그리고 추가로 각 autoencoder로 추출한 잠재 변수(latent variable)를 t-SNE를 통해 데이터 특징을 가시화하고, 실제로 숫자별로 잠재 변수가 잘 묶이고 분리가 되는지 확인해보겠습니다.


