딥러닝 이야기 / Recurrent Neural Network (RNN) / 1. RNN, LSTM, GRU

작성일: 2022.08.18
시작하기 앞서 틀린 부분이 있을 수 있으니, 틀린 부분이 있다면 지적해주시면 감사하겠습니다.
이번 글의 주제는 Recurrent Neural Network (RNN) 입니다.
RNN은 이미지처럼 고정된 크기의 데이터가 아닌, 가변적인 길이를 가진 자연어를 처리하기 위해 등장한 모델입니다.
이러한 자연어 처리를 위한 RNN 모델 계열 중 유명한 unit들이 있는데, 바로 LSTM과 GRU 입니다.
이러한 RNN 계열의 모델은 transformer가 나오기 전, 자연어 처리에 필수적으로 사용된 모델이었습니다.
그리고 현재까지도 Part-Of-Speech (POS) tagging, 텍스트 감성 분류 등 간단한 task에 대해서는 꽤나 좋은 성능을 보여주기도 합니다.
이 글에서는 RNN의 원리와 종류에 대해 살펴보도록 하겠습니다.
그리고 RNN이 어디에 사용되는지, 유명한 모델이 무엇이 있는지도 간단하게 살펴보겠습니다.
마지막으로 RNN의 한계에 대해서도 언급하도록 하겠습니다.
오늘의 컨텐츠입니다.
- RNN의 등장 배경
- RNN의 원리
- RNN의 종류
- LSTM
- GRU
- RNN 사용
- RNN의 한계
Recurrent Neural Network (RNN)
”
1. 자연어 데이터의 가변적인 길이 특성
먼저 이미지 분류 모델과 텍스트 감성 분류에 대해 생각해보겠습니다.
이미지 분류를 위해서 가장 기본적으로 사용할 수 있는 방법은 바로 CNN입니다.
그리고 CNN을 사용하기 위해서는 input으로 들어가는 이미지 데이터는 모두 같은 크기어야 합니다.
이것이 바로 이미지와 텍스트 데이터 사이의 가장 큰 차이점 중에 하나이지요. 왜냐하면 텍스트는 그 길이가 제각각이기 때문입니다.
아래 그림은 고정된 크기의 이미지를 사용하는 모습과 길이가 다른 텍스트 데이터를 사용하는 모습입니다.

이미지 데이터 VS 텍스트 데이터
2. 자연어 데이터 표현의 어려움
자연어는 가변적인 길이 뿐 아니라 표현하는 데 있어서 매우 까다롭습니다.
왜냐하면 이미지는 그 자체로 자연적이고 연속적인 표현을 가지는 데이터이지만, 언어라는 것은 사람들이 만들어 일정한 규칙을 가지고 순서가 중요한 이산적인 데이터이기 때문입니다.
자연어를 표현하기 위해서 아래와 같은 방법을 생각할 수 있습니다.
- One-Hot encoding One-Hot encoding의 방법은 모든 단어 사전을 구축하고, 특정 문장이 가지고 있는 단어들을 1, 나머지 단어들을 0으로 나타내어 벡터화하는 방법입니다. 사실 이는 얼핏 들어도 말이 안되는 방법입니다. 실제로 단어의 종류는 무수히 많으며 당장 우리가 떠오르는 단어들도 수만가지가 될 것입니다. 만약 "I love you"라는 문장에 대해 One-Hot encoding으로 나타내라고 하면 3개의 단어만 1, 나머지 vocab의 단어는 0이 되며 데이터는 거의 0에 가까운 아주 sparse한 벡터가 나올 것입니다. 뿐만 아니라 "I am John whose friend of Mary."와 "I am Mary whose friend of John."은 전혀 다른 뜻임에도 불구하고 같은 표현을 가지게 됩니다.
- Bag-of-Word (BoW) 또다른 방법은 word count를 이용하는 것입니다. 즉 빈도수를 이용하는 것이죠. 예를 들어, "I gave the ball to John, who gave it to Mary."는 {I:1, gave:2, the:1, ball:1, to:2, John:1, who:1, it:1, Mary:1}의 표현을 가지게 됩니다. 이또한 수많은 vocab 중에서 일부가 될것이며, One-Hot encoding 방법처럼 sparse한 벡터로 표현된다는 문제점이 있습니다. 추가로 "I gave the ball to Mary, who gave it to John."은 위의 문장과 전혀 다른 뜻임에도 불구하고 같은 표현을 가지게 된다는 문제점도 있습니다.
Vanilla RNN
RNN에서 R은 recurrent의 약자입니다. 즉 반복, 회귀를 의미합니다.
이러한 이름이 붙여진 이유는 아래 그림을 보면서 설명하도록 하겠습니다.
먼저 맨 처음 hidden state는 우리가 정해주어야 합니다. 기본적으로 유명한 초기화 기법으로 초기화 하거나, 0으로 세팅을 합니다.
그리고 weight는 세 종류가 있습니다. 바로 빨간 화살표에 해당하는 \(W_h\)와 파란 화살표에 해당하는 \(W_x\) 부분, 그리고 보라색 화살표에 해당하는 \(W_y\)입니다.
\(W_h\)는 이전 hidden state에서 다음 hidden state를 예측하는 가중치이고, \(W_x\)는 각 time step별로 들어오는 값들을 매핑하여 hidden state로 보내주는 가중치입니다.
그리고 \(W_y\)는 각 결과를 예측할 때 사용되는 가중치입니다.
여기서 중요한 것은 \(W_h\)는 각 time step별로 모두 같은 가중치를 공유하고, \(W_x\), \(W_y\)도 time step에 상관없이 똑같은 가중치를 공유합니다.
즉 파란색은 모두 같은 가중치가 공유되며, 빨간색끼리도, 보라색끼리도 모두 같은 가중치가 공유됩니다. 이렇게 공유된 가중치는 time step별로 들어오는 데이터에 따라 학습되는 것이지요.
이렇게 가중치를 공유함으로써, 자원의 소모가 줄어들며 가변적인 길이에 유연하게 대응할 수 있습니다. 이것이 바로 vanilla RNN의 원리입니다.
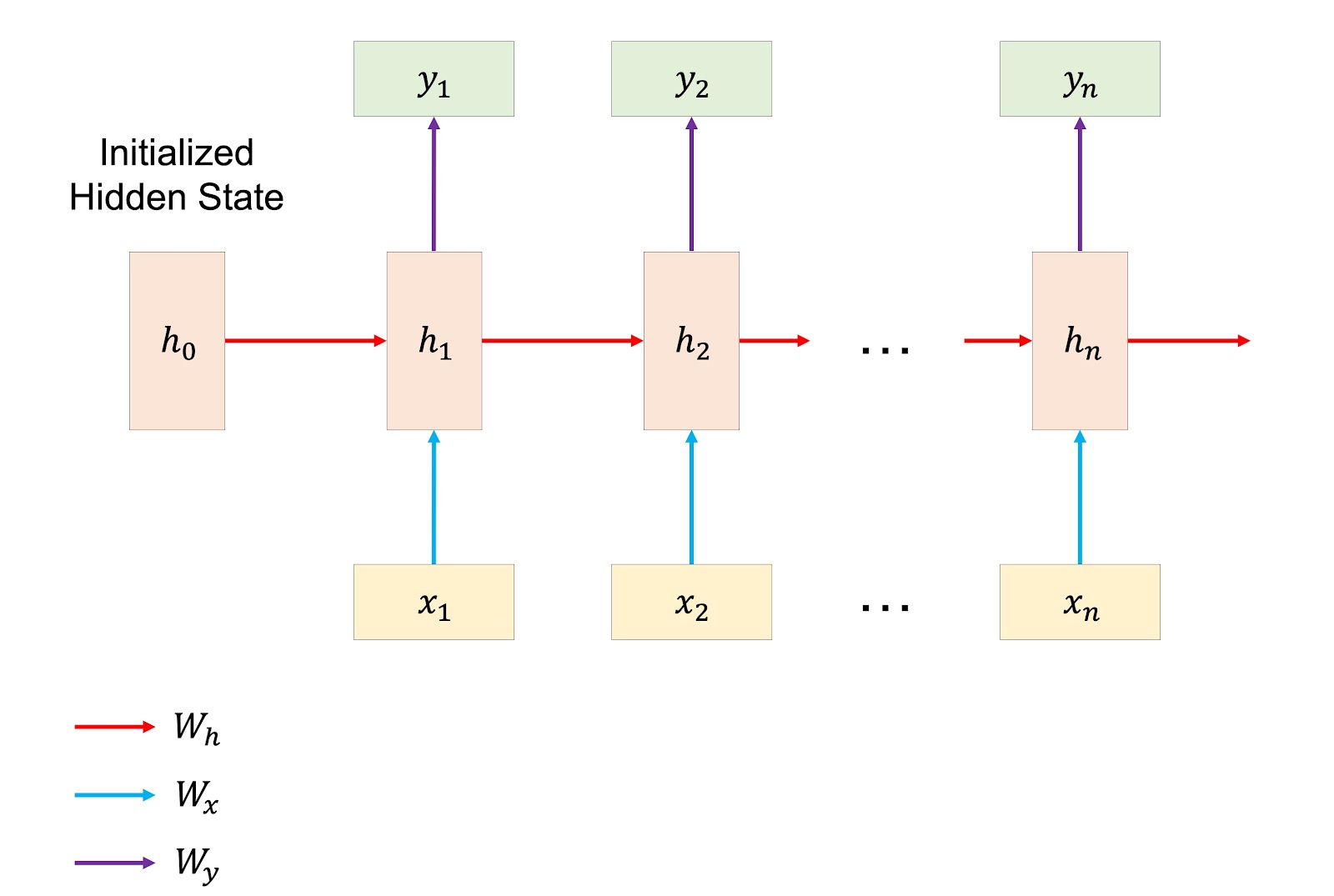
Vanilla RNN 구조
위의 RNN을 수식적으로 나타내면 아래와 같습니다.
이렇게 RNN은 가중치를 매 time step마다 공유하기 때문에 아래와 같은 그림으로도 나타낼 수 있습니다.
아래 그림은 RNN을 나타내는 아주 대표적인 그림이지요.

Vanilla RNN 구조
위에서 vanilla RNN을 살펴보았기 때문에 여기서는 RNN 계열 모델 중 가장 많이 사용되는 Long Short-Term Memory (LSTM)와 Gated Recurrent Unit (GRU)에 대해 살펴보겠습니다.
LSTM
LSTM은 RNN의 성능을 높이기 위해 RNN을 좀 더 복잡한 계산이 가능하도록 만든 모델입니다.
또한 vanilla RNN의 긴 텍스트 데이터에서 나타나던 gradient vanishing 문제를 어느정도 해결한 모델이기도 합니다.
RNN에서는 단순히 input \(x\), output \(y\), hidden state \(h\)에 대한 weight만을 계산하였지만 아래 그림처럼 LSTM은 RNN보다 많고 복잡한 연산이 존재합니다.

LSTM 구조, 출처: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
이제 위 그림에서 LSTM cell을 하나 떼서 살펴보겠습니다.
아래 두 그림은 모두 같은 LSTM cell을 나타내지만, (b)의 그림이 좀 더 이해하기 쉽게 나와있으니 참고하시면 됩니다.

LSTM Cell
이제 수식을 한 번 살펴보겠습니다.
여기서 \(W\)는 input \(x\)에, \(U\)는 hidden state \(h\)에 해당하는 가중치입니다.
그리고 vanilla RNN과 다르게 LSTM은 hidden state \(h_0\)뿐 아니라 cell state에 해당하는 \(c_0\)의 초기값을 사용자가 지정해야 합니다.
또한 수식에 나오는 \(\circ\) 연산은 행렬곱이 아닌 element-wise multiplication을 의미합니다(같은 위치의 행렬 요소끼리 단순 곱하는 연산).
- Forget gate (0 ~ 1): 과거 정보를 기억할지 여부를 결정하는 gate, 1에 가까울수록 과거 정보를 가지고 있음. \(f_t=\sigma(W_fx_t+U_fh_{t-1}+b_f)\)
- Input gate (0 ~ 1): 현재 들어온 정보를 기억할지 여부를 결정하는 gate, 1에 가까울수록 현재 정보를 유지. \(i_t=\sigma(W_ix_t+U_ih_{t-1}+b_i)\)
- Output gate (0 ~ 1): 어떤 정보를 내보내서 hidden state \(h_t\)를 업데이트 할지 결정하는 gate, 1에 가까울수록 hidden state를 업데이트 하는 데 사용. \(o_t=\sigma(W_ox_t+U_oh_{t-1}+b_o)\)
- Next Cell State: 다음 cell에 들어갈 cell state \(c_t\). \(c_t=f_t\circ c_{t-1} + i_t\circ tanh(W_cx_t+U_ch_{t-1}+b_c)\)
- Next Hidden State: 다음 hidden에 들어갈 hidden state \(h_t\). \(h_t=o_t\circ tahh(c_t)\)
GRU
이번에는 GRU에 대해 알아보도록 하겠습니다. GRU는 한국인 조경현 교수께서 개발한 모델입니다. Vanilla RNN이 가지고 있던 gradient vanishing 현상을 다양한 연산을 통해 해결하려고 한 부분은 LSTM과 그 취지가 동일합니다. 하지만 LSTM보다 간단한 구조를 가지고 파라미터 수가 적어 LSTM cell 보다 학습 속도가 빠르다는 장점이 있습니다.

GRU cell 구조
이제 수식을 한 번 살펴보겠습니다.
여기서 \(W\)는 input \(x\)에, \(U\)는 hidden state \(h\)에 해당하는 가중치입니다.
그리고 LSTM과 다르게 cell state에 해당하는 \(c_0\)의 초기값을 지정해야할 필요가 없습니다.
그리고 LSTM의 forget, input, output의 3개의 gate를 update, reset gate의 2개로 줄인 모델이 바로 GRU 입니다.
또한 수식에 나오는 \(\circ\) 연산은 행렬곱이 아닌 element-wise multiplication을 의미합니다(같은 위치의 행렬 요소끼리 단순 곱하는 연산).
- Update gate (0 ~ 1): LSTM의 forget, input gate와 비슷한 역할을 하며 과거와 현재의 정보를 각각 얼마나 반영할지에 대한 비율을 구할 때 사용됨. \(z_t=\sigma(W_zx_t+U_zh_{t-1}+b_z)\)
- Reset gate (0 ~ 1): 다음 \(h_t\)를 구성할 때 얼마나 \(h_{t-1}\)을 반영할지를 결정, 1에 가까울수록 \(h_{t-1}\)을 많이 반영. \(r_t=\sigma(W_rx_t+U_rh_{t-1}+b_r)\)
- \(\tilde{h}\): 다음 hidden state \(h_t\)를 예측할 때 사용되는 중간 계산 과정, 여기서 reset gate가 사용. \(\tilde{h}=tanh(W_hx_t+r_t \circ U_hh_{t-1}+b_h)\)
- Next Hidden State: 다음 hidden에 들어갈 hidden state \(h_t\), 여기서 update gate가 사용되며, \(z_t\)와 \(1-z_t\)는 각각 과거와 현재 정보 비율을 의미. \(h_t=z_t\circ h_{t-1} + (1-z_t)\circ \tilde{h_t}\)
마지막으로 LSTM과 GRU를 비교해보겠습니다. 사실 성능 측면에서는 어떤 게 더 낫다 이런 부분이 뚜렷히 없습니다. 단순히 GRU는 LSTM보다 파라미터 수가 적고 복잡하지 않아 학습이 빠르다는 장점이 있을 뿐입니다. 경험적으로는 데이터가 많을수록 LSTM이, 데이터가 적으면 GRU의 성능이 더 좋은 경향이 있다고는 합니다만 이는 계산의 복잡성이 반영된 결과로 보입니다. 사실 본인의 task에 따라 어떤 것이 성능이 더 좋을지는 아무도 모르기 때문에 실험적으로 두 개 다 사용해보고 결과가 좋은 cell을 사용해야 할 것입니다.
- Sequence-level Classification: 모델의 맨 마지막 결과 혹은 hidden state를 이용해 분류
- Sentiment Classification (감성 분류): 긍정의 문장인지 부정의 문장인지 분류.
- Topic Classification (주제 분류): 텍스트가 어떤 주제인지 분류.
- Step-level Classification: 각 step별 모델의 결과를 이용해 분류
- Part-Of-Speech (POS) tagging (품사 태깅): 각 step에 들어오는 input이 어떠한 품사인지 분류.
- Named Entity Recognition (NER, 개체명 인식): 각 step에 들어오는 input이 어떤 개체인지 분류.
- Language Modeling (LM): 아래에 자세히 설명.
- Bidirectional Model: 데이터의 양방향성을 모두 고려할 수 있게끔 모델을 구성. 위의 예시들도 bidirectional model로 구현 가능.
- Sequence-to-sequence (다음글 참고)
- Machine Translation (기계 번역): 서로 다른 두 언어를 번역.
- Question Answering (QA, 질의응답): 들어온 질의에 대해 답변을 생성.
- Chit-chat Chatbot (챗봇): 들어온 대화에 대해 답을 생성하는 대화 모델.
Language Modeling (LM)
LM은 현재 자연어 처리에서 아주 보편적으로 자리잡은 기법입니다. 어떤 사람들인 LM을 pre-task의 일종으로 보는 시선도 있는데, 이는 그만큼 LM을 하면서 모델이 학습할 수 있는 정보가 아주 많기 때문입니다. 그렇다면 LM은 무엇일까요? 바로 이전 데이터로 들어온 문장 요소를 보고 다음에 나올 단어를 예측하는 기법입니다.
예를 들어 "This movie is" 다음에 올 단어 중 어떤 단어의 확률이 더 높냐 따졌을 때, "interesting"과 "boy" 중에 당연히 전자의 확률이 높겠지요. LM은 이러한 문장들을 대량으로 넣고 각 문장별로 다음에 올 단어를 예측하게끔 하는 것입니다. 그리고 이렇게 학습한 모델을 우리는 자기 회귀 모델, autoregressive 모델이라고 합니다. "I" 다음에 "love"나 "like"이 올 확률은 별반 다르지 않을 것입니다. 하지만 "I like reading" 다음에 "car"과 "book" 중에서는 당연히 후자가 올 확률이 높겠지요. 이렇게 LM이 잘 되었다면 이전 데이터가 주어졌을 때, 모델은 적절한 단어를 충분히 예측할 수 있습니다. 그리고 모델이 가장 높은 확률의 단어들만 선택하는 기법을 greedy search, branch를 이용해서 가장 높은 확률 tok-k를 뽑아주는 기법을 beam search라고 합니다.
또다른 하나의 예시를 들어보겠습니다. "This movie is as impressive as a preschool Christmas play"의 문장을 수학적인 확률로써 나타내기 위해서는 어떻게 써야할까요? 다른 말로 아래의 확률을 구하는 것이지요.
이 문장의 확률은 아래와 같이 조건부 확률의 곱으로 표현할 수 있습니다.
즉 다른 말로 하면 어느 문장의 확률은 아래 수식과 같이 t번째 단어를 1 ~ t-1번째 단어들을 가지고 예측한 확률들의 곱셈이 됩니다.
이러한 확률 식이 나오게 되는 이유는 바로 Bayes' theorem을 이용하는 것입니다. 간단히 말해 조건부 확률 공식을 이용하여 나온 결과입니다.
사실 과거에는 이러한 문장을 가지고 LM을 하기 위해서 bigram, trigram 등의 방법이 많이 쓰였습니다.
왜냐하면 실질적으로 모든 문장의 단어별로 조건부 확률을 계산하는 것은 자원의 낭비이고, 연산량이 많기 때문입니다.
그래서 모든 문장의 단어를 확률로써 나타내는 대신 두 묶음 혹은 세 묶음처럼 묶음 단위로 계산을 하였던 것입니다.
- Bigram: \(p(w_t|w_{t-1})\)
- Trigram: \(p(w_t|w_{t-2}, w_{t-1})\)
그리고 위와 다르게 RNN 모델을 가지고 모델링을 하는 것은 이론적으로 모든 단어를 반영할 수 있는 것이지요. 이렇듯 LM은 기계 번역, 챗봇 등 다양한 분야에서 기본이 되는 학습 기법이고, transformer, GPT, BART 등 많은 모델들이 LM을 통해 학습하는 autoregressive 모델인 것입니다.
- RNN: \(p(w_t|w_1, w_2, ..., w_{t-1})\)
마지막으로 각각의 모델 RNN, LSTM, GRU의 장단점을 살펴보고 마무리 하겠습니다.
- Vanilla RNN
- 장점
- 연산이 단순하여 속도가 빠름.
- 단점
- 긴 문장의 데이터에 대해 gradient vanishing 문제가 발생(Backpropagation이 멀리까지 전달이 안되기 때문).
- 과거 문장의 데이터의 기억이 손실.
- Gradient exploding 발생.
- LSTM
- 장점
- Forget, input, output gate를 통해 과거 데이터를 유지하기 때문에 RNN에 비해 긴 문장에 더 적절함.
- 각각의 메모리의 결과를 제어 할 수 있음.
- 단점
- 메모리가 덮어 씌워질 가능성이 있음.
- 연산이 복잡하여 속도가 상대적으로 느림.
- GRU
- 장점
- Update, reset gate를 통해 과거 데이터를 유지하기 때문에 RNN에 비해 긴 문장에 더 적절함.
- 메모리가 덮어 씌워질 가능성이 없음.
- LSTM에 비해 연산이 적어서 속도가 빠름.
- 단점
- 각각의 메모리의 결과를 제어 할 수 없음.
다음에는 sequence-to-sequence 모델과, 현재에 들어서는 아주 기본이 되는 기법인 attention에 대해 살펴보도록 하겠습니다.


