딥러닝 이야기 / Generative Pre-Training Transformer (GPT) / 1. GPT-1, GPT-2, GPT-3

작성일: 2023.01.07
시작하기 앞서 틀린 부분이 있을 수 있으니, 틀린 부분이 있다면 지적해주시면 감사하겠습니다.
이번에 소개할 모델은 바로 OpenAI의 Generative Pre-Training Transformer (GPT) 입니다.
이름에서부터 알 수 있듯이 이 모델은 transformer의 decoder를 기반으로 하는 모델입니다.
그중에서 GPT-1, GPT-2, GPT-3을 소개하겠습니다.
GPT 모델 또한 강력한 언어 모델 중 하나이며, 현재는 ChatGPT 까지 엄청난 성능을 보여주고 있습니다.
GPT도 많은 종류가 있는데 그중 GPT-1, GPT-2, GPT-3를 소개할 예정입니다.
사실 GPT-3부터는 모델이 엄청 커서 일반적인 상황에서 사용하는 데 어려움이 있습니다.
그리고 최근에 등장한 ChatGPT 또한 GPT-3.5를 기반으로 하는데 이 모델도 일반적인 상황에서 사용하기 어려울뿐더러 fine-tuning 하기에도 벅찬 모델입니다.
위의 모델은 공개 되지도 않아서 우리가 불러와서 사용하기도 불가능하지만 GPT-1,2는 비교적 모델이 가볍고 Hugging Face의 API에서도 불러와 사용가능한 모델입니다.
아래는 GPT 논문 링크입니다.
오늘의 컨텐츠입니다.
- GPT-1
- 등장 배경
- 장점
- 모델 구조
- Pre-training
- 여러 Task 결과
- GPT-2
- 등장 배경
- 장점
- 모델 구조
- Pre-training
- 여러 Task 결과
- GPT-3
- 등장 배경
- 모델 구조
- Pre-training 및 모델 평가 방법
- 여러 Task 결과
- 한계
GPT
”
GPT-1은 BERT가 나오기 전에 OpenAI의 기술 리포트에서 처음 공개되었습니다(BERT 설명은 이전글을 참고).
GPT-1은 transformer decoder의 encoder-decoder attention을 제외한 모델입니다(transformer 설명은 이전글을 참고).
그럼 먼저 GPT-1이 나오게 된 간단한 등장 배경을 살펴보겠습니다.
등장 배경
먼저 텍스트는 인터넷상에 많은 데이터가 있습니다. 하지만 그중에서 특정 학습을 위해 label이 된 데이터는 많지 않습니다.
즉 label이 되지 않은 데이터는 많은데 label 된 데이터가 적다는 사실에서 시작합니다.
이에 따라 GPT-1의 목표는 label이 없는 텍스트를 이용하여 unsupervised pre-training을 한 후, label 된 텍스트 데이터를 통해 목적에 맞게 fine-tuning 할 수 있는 모델이 되자는 것입니다.
장점
위에서 설명한 방식을 사용함으로써 GPT-1의 장점이 하나 더 등장하게 되는데, GPT-1의 모델은 특정 task를 위한 모델 구조를 가지는 것이 아니라, pre-trained 된 모델의 가장 끝에 하나의 linear layer만 붙여놓고 여러 목적에 맞는 task fine-tuning이 가능하다는 것입니다.
지금에야 pre-trained 모델을 가져와서 fine-tuning하는 방식을 많이 사용하지만, 이때는 아주 획기적인 아이디어였습니다.
Pre-trained 모델에 linear layer만 하나만 붙여서 fine-tuning 하는 대신에, 여러 task를 위해서 각각의 목적에 맞게만 input을 변화시켜 사용할 수 있다는 장점인 것이지요.
그 여러가지 사용 예시가 아래 그림과 같습니다.
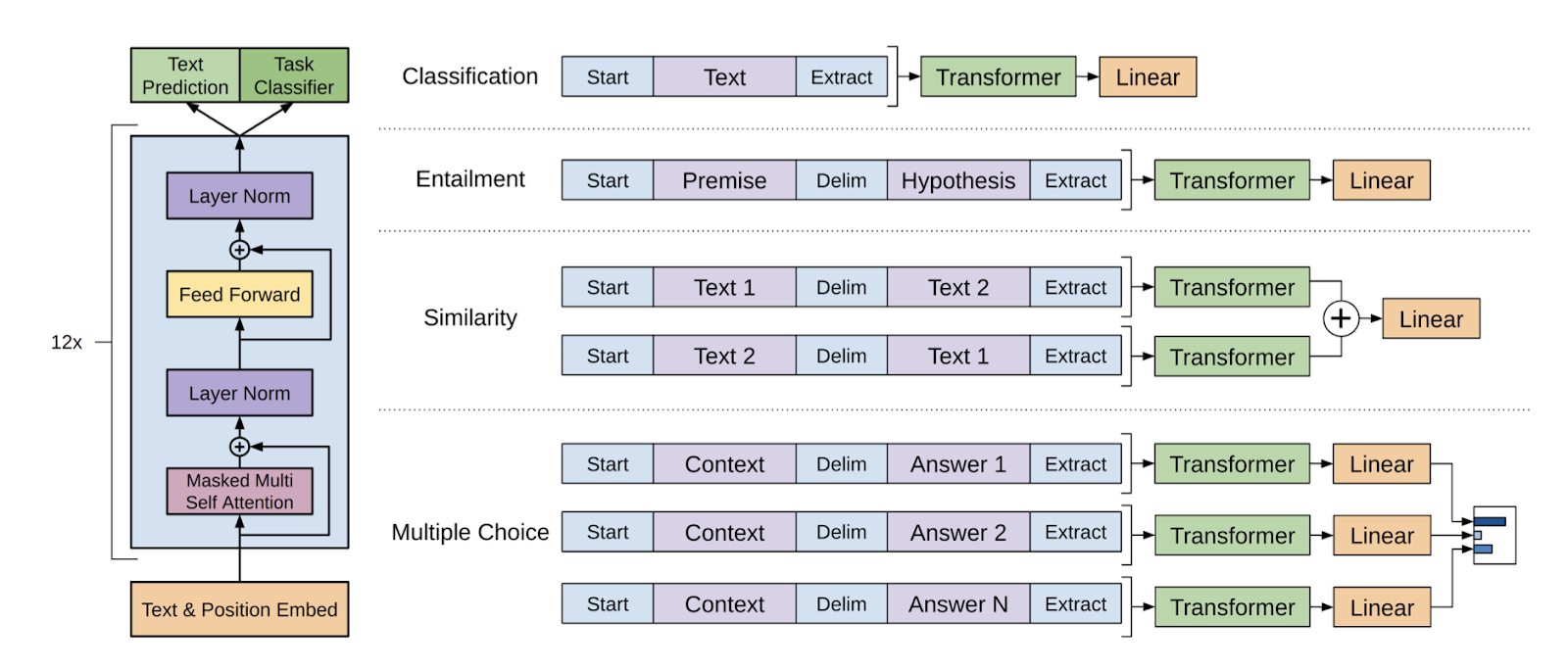
GPT-1 구조 및 여러 task 적용 방법, 출처: GPT-1 논문
위 그림을 보게 되면 classification은 단순히 하나의 문장을 넣고, entailment같은 경우 두 문장을 이어붙여 넣습니다.
그리고 단순히 linear layer 하나만을 사용하는데, 이렇게 input만 바꾸고 fine-tuning 하자는 것이 바로 GPT-1의 주장입니다.
모델 구조
이제 GPT-1은 어떠한 구조를 가지는지 살펴보면, GPT-1은 단순히 transformer decoder 구조를 사용합니다.
그리고 encoder가 없기 때문에 causal mask가 적용된 decoder self attention만 존재하고 encoder-decoder attention은 없는게 특징입니다.
아래 그림을 보면 transformer decoder의 encoder-decoder attention이 없는 것을 확인할 수 있죠.
Transformer decoder 와 GPT-1 구조
Pre-training
이때까지 GPT-1의 목표는 pre-training이 잘 이루어진 모델을 바탕으로 fine-tuning 하는 것이라고 이야기 했습니다.
그렇다면 어떠한 pre-training 방법을 사용할까요?
바로 우리가 잘 아는 일반적인 언어 모델을 학습하는 방법인 autoregressive한 방법을 사용합니다.
즉 다음 토큰을 잘 예측하도록 cross-entropy loss를 사용하여 학습을 하는 것입니다.
이 방법은 번역, 캡셔닝 등 decoder가 있는 모델에서 흔히 사용하는 방법이라 잘 아실 것이라 생각합니다.
이러한 방식으로 7,000개의 책 데이터, 1B Word Benchmark 데이터로 학습을 진행 했습니다.
여러 Task 결과
GPT-1은 이러한 방식으로 pre-training을 한 후, fine-tuning으로 다양한 task에서 state-of-the-art (SOTA)를 달성합니다.



GPT-1 여러 실험 결과
”
등장 배경
GPT-1은 좋은 pre-trained 모델을 바탕으로 task에 맞게 fine-tuning 하는 데 초점을 맞추고 있습니다.
반면 GPT-2는 언어 모델을 잘 학습하여 fine-tuning 없이 zero-shot으로 바로 적용할 수 있는 범용적인 모델, 즉 일반화가 잘 된 모델을 학습하는 것이 목적입니다.
장점
먼저 저자들은 빅 데이터로 거대한 모델을 학습하는 것은 task에 있어서 강점을 보이지만, 데이터의 분포가 조금만 달라지면 모델의 성능이 낮아진다고 언급합니다.
이러한 모델을 저자들은 "Narrow Expert"라고 표현합니다.
저자는 이렇게 민감한 모델 대신 일반화가 잘되는 GPT-2 모델을 학습하는 것을 목표로 하며, 이에따라 GPT-2는 원하는 task에 대해 training dataset을 구축할 필요가 없다는 장점이 있습니다.
모델 구조
모델 구조는 GPT-1과 흡사하지만, layer normalization의 위치가 달라집니다.
실제로 제가 Hugging Face GPT-2 구현된 모델을 확인했을 때 아래 그림과 일치하는 것을 확인했습니다.

GPT-1, GPT-2 구조
Pre-training
GPT-2 모델도 여느 language modeling과 동일하게 autoregressive 방법으로 학습합니다.
다만 일반화된 모델 학습을 위해 다양한 주제에 대해 GPT-1 학습보다 더 많은 데이터를 사용합니다.
기존에 사용되는 텍스트 데이터는 wikipedia 등 단일 domain에서 수집된 텍스트가 많다고 판단하여 다양성을 위해 인터넷, 특히 Reddit에서 모은 글을 포함하여 40GB가 넘는 텍스트를 직접 수집하여 학습합니다.
또한 기존에 있던 인터넷 crawling 데이터는 품질이 나쁘다고 판단하여, 사람들이 직접 수집하여 중복 제거 등 필터링을 하고 검증과정을 거쳐 40GB나 되는 WebText 데이터셋을 구성한 후 학습을 한 것 입니다.
즉 사람이 직접 검수하고 다양성을 고려한 대용량의 데이터로 학습한 것입니다.
여러 Task 결과
GPT-2는 BPE 토크나이저를 사용해서 텍스트에 상관없이 전처리를 하지 않고도 바로 적용할 수 있다는 장점이 있습니다.
실제로 unknown 토큰이 400억 byte 중 26개밖에 나타나지 않는다고 합니다.
그리고 아래는 zero-shot으로 여러개의 데이터에 대해 적용해본 결과입니다.
놀랍게도 fine-tuning을 하지 않았음에도 불구하고 마지막 1BW (One Billion Word) 데이터를 제외하고는 모두 SOTA를 달성하였습니다.

GPT-2 zero-shot 결과
이외에도 Children's Book Test, Winograd Schema Challenge (text ambiguity 해석 능력 판단) 데이터셋에 대해서도 우월한 성능으로 SOTA를 내어줬습니다.
물론 모든 task에 좋은 결과를 내어준 것은 아닙니다.
Summarization은 이전 task보다 좋지는 않지만 준수한 성능을 보였고, 기계 번역의 결과(Fr→En: BLEU=11.5, En→Fr: BLEU=11.5)는 상대적으로 다른 task들에 비해 낮은 성능을 보여주었습니다.

GPT-2 summarization 결과 결과
저자들은 마지막으로 사용한 training set과 test set의 겹치는 비율을 정량화 하였습니다. 예를들어 CIFAR10 같은 경우는 train/test set이 3.3%가 겹친다고 합니다.
이는 data memorization을 유발하여 모델의 일반화 성능이 떨어지고, 성능 평가가 객관적이지 않을 수 있기 때문입니다.
따라서 저자는 8-gram bloom 필터를 만들어서 이때까지 성능 평가에 사용되었던 test set과 본인들이 구축한 WebText training setrhk overlapping 비율을 계산하였습니다.
그 결과 저자들이 구축한 WebText는 겹치는 비율이 기존 데이터셋에 비해 많이 겹치지 않는 모습을 보이며, WebText 데이터로 학습했을 때 높은 성능을 보이는 것을 다시 한 번 놀라게 합니다.
그와 동시에 이러한 데이터 중복 제거를 위해 필터를 사용할 것을 권장합니다.

Dataset overlapping 비율
그리고 저자들은 모델이 커질수록 GPT-2가 WebText 데이터셋에 대해 loss가 낮아지는 것을 보아 underfitting이 되었고, data memorization은 일어나지 않는다고 주장합니다.
GPT-2는 random 모델보다 떨어지는 성능도 있고 번역같은 경우 좋은 성능을 내지는 못했지만, zero-shot을 위한 언어 모델을 연구했다는 점과, 성능이 좋았던 task도 많았기에 더 깊은 의의가 있는 연구인 것 같습니다.
”
등장 배경
언어 모델의 추세는 task-agnostic (task에 상관 없이 범용적인)한 모델을 pre-training 하여 만들어놓고 downstream task로 활용하는 것입니다.
이렇게 downstream task에 적용하여 fine-tuning하는 방법은 효과적이고 성능이 좋다는 장점이 있지만 여전히 아래와같은 문제점이 존재합니다.
- Fine-tuning을 위해서는 여전히 labeling 된 데이터가 필요하며 이는 비효율적이다.
- 빅 데이터를 통해 거대 모델을 pre-training 후 작은 데이터로 fine-tuning을 한다면, 매우 좁은 분포의 데이터를 학습하게 되며 이는 거짓 상관관계를 학습하게 될 수 있고 이에따라 일반화 성능이 떨어질 수 있다.
- 사람은 특정 task를 학습하는 데 많은 데이터가 필요로하지 않다. 몇가지 지시사항 혹은 사람의 능력에 의해 새로운 task를 수행하는 것이 가능하다.
실제로 GPT-2는 이러한 meta-learning 기법 중 하나인 방법으로 학습되었다고 하며, 그들은 이러한 방법을 "in-context learning"이란 용어를 사용합니다. 아래 그림을 보면 첫 번째 문맥은 계산, 두 번째 문맥은 오타 교정, 세 번째 문맥은 번역임을 알 수있습니다.

Meta-learning 기법 중 in-context learning, 출처: GPT-3 논문
하지만 GPT-2를 학습할 때도 이러한 방법으로 학습을 하였지만 GPT-2 부분에서 설명 했듯이 모든 결과에서 성능이 좋지 못했습니다.
따라서 저자는 BERT < GPT-2 < Megatron-lm < T5 < Project Turing 순서로 파라미터수가 커지는데 이들이 파라미터가 커질수록 성능이 향상되고 loss가 줄어드는 경향을 보아 모델을 더 키우면 되겠다고 생각한 것입니다.
이렇게 하여 15억개의 parameter를 가지는 GPT-2의 100배가 넘는 1,750억개의 parameter를 가지는 초거대 언어 모델 GPT-3가 등장한 것입니다.
그리고 실제로 아래 그림처럼 모델이 커질수록 더 좋은 성능을 냈다고 합니다.

GPT-3 모델 크기에 따른 성능, 출처: GPT-3 논문
모델 구조
모델 구조는 GPT-2와 동일하다고 합니다. 다만 GPT-2에서 더 많은 양의 데이터를 더 큰 모델로 학습한 것이지요.
다만 attention 패턴을 메모리 사용량을 줄이기 위해 제안됐던 sparse transforemer에 사용한 패턴을 사용했다고 합니다.

Sparse transformer attention 패턴, 출처: Sparse transformer 논문
Pre-training 및 모델 평가 방법
모델, 데이터, pre-training은 기본적으로 GPT-2와 같다고 합니다
다만 다른 점은 더 커진 모델과 데이터의 양 그리고 데이터의 다양성 및 학습 시간을 늘렸다고 합니다.
In-context learning으로 pre-training 한 부분도 GPT-2와 동일하지만, 다만 다른점은 평가 방법을 다르게 했다고 합니다.
그리고 동시에 저자는 4가지의 평가 방법을 소개합니다.
- Fine-tuning (GPT-3는 task-agnostic 모델 학습을 목표로 하기 때문에 평가할 때 사용하지 않음)
- Zero-shot
- One-shot
- Few-shot

모델 성능 평가 4가지 방법, 출처: GPT-3 논문
위에 그림에서 zero-shot인 경우, task를 설명하는 문구만 넣어주고 나온 대답으로 평가합니다.
One-shot은 task를 설명하는 문구와 더불어 그에 해당하는 예시 하나를 넣어주고 나온 대답으로 평가합니다.
Few-shot은 task를 설명하는 문구와 더불어 그에 해당하는 예시 몇가지를 넣어주고 나온 대답으로 평가합니다.
단 위의 경우에서 해당하는 예시에 대해 fine-tuning을 하지 않는 것이 핵심입니다.
여러 Task 결과
저자들은 24개 이상의 NLP 데이터셋에서 GPT-3을 평가합니다.
결과는 너무 많기 때문에 논문에서 직접 참고하시면 될 것 같습니다.
다만 놀라운점은 GPT-3는 few-shot 평가의 경우 일부 SOTA에 필적하거나 SOTA를 달성한 경우도 있었습니다.
뿐만 아니라 zero-, one-, few-shot의 순서로 평가 성능이 좋아지는 경향도 있었습니다.
한계
한계를 간단히 정리해보겠습니다.
- GPT-2와 비슷하게 몇가지의 task에 대해 한계가 존재(일반 상식, 독해 등).
- GPT-3는 transformer decoder를 이용하여 autoregressive학 학습하기 때문에 bi-directional한 부분 파악의 한계가 존재.
- Loss function으로 모델을 학습하는 것은 실제 세상과 상호작용이 아닌 task에 집중 되기 때문에 근본적인 한계가 존재.
- GPT-3는 한 명의 사람이 평생 보는 것 이상의 텍스트를 보고 학습을 해도 사람의 능력을 뛰어넘지 못함.
- Few-shot의 성능 평가 방법이 학습 했던 task를 기억하고 내어주는 것인지, 스스로 문제를 인식하고 답을 내어주는 것인지 판별이 안됨.
- 학습 중간에 오류가 발견되어도 학습을 중단할 수 없었던 것처럼 한 번 학습 하는 데 엄청난 비용과 자원 소모가 이루어짐.
- 학습이 black box 모델이며, 데이터의 편향을 스스로 없애지 못하고 그대로 유지 됨.
- 악용, 성차별, 성편견, 공정성 등 ethical issue 문제가 나올 수 있음.
지금까지 GPT-1, GPT-2, GPT-3에 대해 살펴보았습니다.
GPT-2까지는 실생활에 적용이가능하지만, GPT-3부터는 공개 되지도 않았지미ㅏㄴ 1,750억개의 parameter를 가지기 때문에 일반적으로 가져와서 사용하기에 한계가 있습니다.
다만 GPT-3는 언어 모델의 엄청난 성능을 보여주고, 이 논문은 앞으로 나아가야할 방향을 제시해준 논문입니다.
현재 GPT-3.5와 GPT-3.5를 활용하여 나온 ChatGPT도 엄청난 화제가 되고 있습니다.
실제로 GPT-3.5를 사용해본 결과 오류가 몇가지 보긴 했지만 미적분의 복잡한 수식 풀이, 번역, 서울 지하철 4호선 역 개수 등 알기 힘든 정보를 물어보았을 때 역 개수 같은 것은 틀리긴 했지만 대부분의 task에 정확한 답을 알려주었습니다.
이를 통해 앞으로의 언어 모델 발전이 기대가 됩니다.
다음에는 GPT-2를 이용하여 multi-turn 챗봇 model 학습을 해보겠습니다.


